
※この記事は「インストール手順」ではなく、
実務での“成果物”を
最短で出すための使い方
にフォーカスします。
※モデル名や上限などは更新されるため、
本文は 2026年1月時点の情報をベースにしています
(必要に応じてあなたの環境の表示に
合わせて調整してください)
この記事でわかること
- ChatGPTの
仕事の成果に直結する視点で把握できる - Auto /Instant /Thinking/Proの
違いと、迷わない選び方がわかる - 分析・検索・画像認識・解析・調査等
実務8パターンのイメージが手に入る
まずはじめに(ChatGPTについて)
最近、ニュースやSNSでその名を
聞かない日はない「ChatGPT」。
一言で言えば、
「まるで人間との対話かのように、
自然な文章でやり取りができるAI
(人工知能)」
です。
アメリカのOpenAI社が
開発したこのツールは、
単なる検索エンジンとは一線を画します。
知りたいことを教えてくれるだけでなく、
あなたの「パートナー」として、
以下のような
様々なタスクをこなしてくれます。
ChatGPTにできることの例
- 日常の相談:
「冷蔵庫にある余り物で作れるレシピは?」 - ビジネスの効率化:
「会議の議事録を要約して」
「丁寧な断りメールの文面を作って」 - クリエイティブな活動:
「ブログのタイトル案を10個出して」
「物語の続きを考えて」 - 学習のサポート:
「量子力学を、小学生にも理解可能に説明して」
なぜ、こんなに話題なの?
それは、ChatGPTが「文脈」を理解するからです。
これまでのAIは、決まった質問に
決まった回答を返すだけでしたが、
ChatGPTは前の会話の流れを汲み取り、
より深く、よりパーソナライズされた
提案をしてくれます。
まさに、
24時間いつでも
相談に乗ってくれる、
博識なアシスタント
が手に入ったようなものです。
ChatGPTの他にも、
様々なAIサービスがあり、
代表的なものは以下です。
ChatGPTプラン比較
| 無料 | Go | Plus | Pro | Enterprise | |
|---|---|---|---|---|---|
| 月額 | 0円 | 1500円 | 3000円 | 30000円 | 要相談 |
| モデル (GPT-5.2) | mini Instant(制限あり) | Auto/標準 Instant | Auto/標準 Instant Thinking | Auto/標準 Instant Thinking Pro | Auto/標準 Instant Thinking Pro(制限あり) |
| メッセージ数 | GPT-5.2 (数時間で数回) | 無料版の 約10倍 | 優先 ほぼ無制限 | 無制限 | ほぼ無制限 Pro 月15回 |
| Deep Research | 月5回 (軽量版) | 月25回まで | 月250回まで | 月25回〜 (契約による) | |
| 画像生成 (1日) | 2枚程度 | 20〜30枚程度 | 200枚程度 | 無制限 | 無制限 |
| 動画生成 | | 利用可能 (回数制限あり) | 優先 高解像度生成 | Proより優先度低 | |
| 用途・特徴 | 検索・校正 | 執筆や画像生成 | 調査・プログラム チェックや壁打ち | 高度なプログラム 市場調査・研究 | 組織の効率化 情報が学習されない |
| 広告表示 | | ||||
Proにいくにつれて、
賢さ・制限もなくなってきます。
出力結果の嘘も減っていきます
自身の使用用途によって
Plan選択を行う形ですね。
今回の利用は
ChatGPT Enterprise
ChatGPT Enterpriseとは(超ざっくり概要)
ChatGPT Enterpriseは、
企業利用を前提に、
セキュリティ/プライバシー/管理機能と、
日々の業務で使うためのツール
(検索、データ分析、ファイルアップロード、Deep research、画像生成…など)
をまとめて提供するプランです。
Proの方が高性能ですが、
企業版はセキュリティ重視
ですね!
Enterpriseの「安心材料」だけ先に押さえる
- 原則、入力・出力データは
学習に使われない(デフォルト) - データ保持期間は
管理者がコントロール可能 - 保存データは暗号化
- 監査・コンプライアンスのための
ログや管理機能も拡張されている
まずはここ:モデルの違い(Auto/Instant/Thinking/Pro)
モデル選びで迷う原因は、性能よりも
「この仕事、速さと深さどっちが必要?」
が曖昧なことが多いです。
先に結論だけ書くと、基本はこうです。
- Auto/標準:迷ったらこれ
(状況に応じて自動で振り分け) - Instant:速く“たたき台”がほしい
- Thinking:論点整理、チェック、
手順化など「失敗できない」系 - Pro:調査や検証を含む、
より“研究グレード”寄り(回数上限あり) - Deep Research:「調査・執筆」をネットから詳細にレポート(回数上限あり)
モデルの特徴を「仕事目線」で整理
Auto:基本これでOK(迷いを減らす)
Autoはモデルピッカー上で、
InstantとThinkingを
自動で切り替える扱いです。
「まずAutoで投げる→出力が薄ければThinkingに切り替えて再実行」が良し!
Instantより思考が深く、
普段使いするには優秀です。
GoプランではInstantが標準で、
標準モデルは制限がある仕様です。
Instant:速い。雑でいい“初速”に強い
- Slack返信/メール下書き
- 箇条書き→文章化
- すでに方向性が決まってる作業の整形
Thinking:深い。構造化/レビュー/多段の推論に強い
- 議事録→決定事項・ToDo化
- 仕様書レビュー(矛盾・未定義語・曖昧表現)
- 障害対応の切り分け(仮説→検証手順)
Thinkingは週あたりの利用上限あり。
(長期的には週200が目安、現在は一時的に上げている旨の記載あり)
Pro:調査・検証まで含める“重い仕事”向き
Proは「研究グレード」とされ、
月あたりのリクエスト上限が
提示されています。
「出典付きでまとめる」
「反証も含めて整理する」など、
成果物の品質を上げたいときに使う枠。
Deep Research:検証・調査のレポートに特化
- 「最新のAI半導体市場のトレンドを
10枚のレポートにまとめて」 - 「競合他社AとBのサービス内容、
価格、評判を徹底的に比較して」 - 「特定のトピックに関する学術論文やニュースを網羅的に集めてほしい」
膨大なネットソースを網羅的に検索し、
検索だけでなく結果から深堀する機能。
出力結果の違い
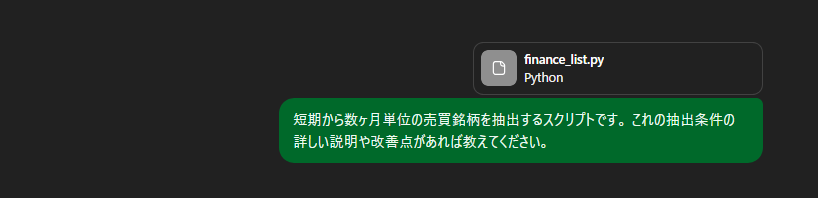
今回は複雑なものでテストするため
作成したコードを渡してみます。
| 標準モデル | Thinking | Pro | |
|---|---|---|---|
| 文書量 | 短め | 中間 | 長い |
| 内容 | 概要・表面的 | 検証・改良まで理解 | 制度思想から戦略まで |
| 改善案 | 追加の提案など数値の適正化を中心として提案 | 今のコード基準から 変更点や修正提案 | 思想から 運用しやすいような 改善提案 |
| 思考時間 | 10秒 | 1分51秒 | 21分36秒 |
主な特徴
標準:今こうなってるよというものを羅列
標準モデルでは、
スクリプトに書かれている条件を
比較的にそのまま読み取り、
「何を条件に、
どこで銘柄が絞られているか」
を整理した出力になりました。
抽出ロジックの流れや、
A/B/Cといったランク分けの
意味を把握するには十分ですが、
なぜその条件なのか、
どこを変えるとどう変わるのか、
の踏み込んだ考察は控えめです。
Thinking:計算式を含めてコードを紹介
他のモデルと比べて
明らかに踏み込みが深く、
各条件について
「なぜこの条件が必要なのか」
「どんな取りこぼしが起きるか」
「ここの変更で性格がどう変わるか」
まで掘り下げています。
特に、
・直近クロス条件による取りこぼし
・当日押し目限定の弱点
・財務フィルタ150件上限の副作用
など実運用で初めて気づきやすいポイント
が明示されており、スクリプトの改善議論に
直結する内容になっています。
Pro:より詳しく計算式や数値を用いて紹介
Proモデルでは、
単なる条件説明にとどまらず、
「この条件はどんな売買スタイルを
想定しているか」
「運用でどんな銘柄が残りやすいか」
といったトレード視点での意味付けが
強くなっています。
例えば、基準線押し目・ATR帯・
流動性制限についても、
“短期〜数ヶ月”という時間軸に
照らして妥当性を評価し、
その結果としてどんな銘柄が集まり
やすいかが言語化されています。
参考(各モデルの実行結果)
以下は、あなたの finance_list.py が「短期〜数ヶ月の売買候補(押し目)」をどう抽出しているかを、条件を分解して説明し、改善アイデアも具体的に挙げたものです。
finance_list
スクリプトの全体像(2段階運用)
1) 夜間(eod / snapshot)
東証プライム全銘柄(get_ticker_list())を対象に、
価格レンジ → 1年日足 → テクニカル判定 →(一部)財務判定で候補を作り、
_cache/snapshot_YYYYMMDD_plXXXXX.pkl に保存します。
finance_list
2) 日中(intraday)
当日スナップショットがなければ「直近のスナップショット」を自動使用(休日でも動く設計)。
A/B と、優先度の高い C(C+→C-)から最大 MAX_INTRADAY_QUOTES 件だけを取り、
1分足も使って現在値・日中安値高値を更新し、
BUY_ZONE に入ったものだけを “今のA/B/C” として出力します。
finance_list
抽出されるランクの意味(A / B / C+ / C-)
A(最優先)
テクニカル条件を全部クリア
さらに 財務フィルタ(PER/PBR/ROE/EPS)もクリア
finance_list
B(次点)
テクニカルは強いが、
財務データが取れない/欠損/閾値外 → B
finance_list
C(監視枠:基準線近辺)
A/Bほど厳しくない「基準線に近い」銘柄を監視用に拾う
さらに C を C+(監視強)と C-(監視弱)に分割しています
finance_list
条件の詳細(夜間スナップショットでの判定)
ここが “抽出条件の本体” です。コード内の流れ(コメントの①〜⑧)に沿って説明します。
finance_list
0) 価格レンジ・ユニバース前処理
まず現在値(直近2日の日足Close)で 500円〜10,000円の銘柄に絞ります
MIN_PRICE=500, PRICE_LIMIT=10000
finance_list
目的:低位株/値が飛びやすい銘柄、超値嵩の扱いづらさを避ける(好みで調整)
A/B の「テクニカル強め候補」条件(全部必要)
① 押し目形状(“押して戻す”)
当日安値が基準線近辺まで触れること(EODでは “日中に押した” を当日安値で代用)
REQUIRE_INTRADAY_TOUCH=True
判定は last_low <= kijun*(1+0.1%)(TOUCH_ABOVE_KIJUN_PCT=0.001)
finance_list
引けは基準線以上(戻して終わる)
REQUIRE_CLOSE_ABOVE_KIJUN=True → close >= kijun
finance_list
さらに 引けが基準線から離れすぎてない
close <= kijun*(1+near_width)(押し目の範囲内)
finance_list
② 基準線が上向き
直近5営業日で基準線が上昇(kijun[-1] > kijun[-6])
finance_list
→ “上昇トレンド中の押し目” を強制
③ 中期トレンド(大きい流れ)
MA50 > MA200 かつ Close > MA50
finance_list
→ 「上昇相場の押し目」寄りに寄せています
④ 短期トレンド(直近の勢い)
MA5 > MA25(状態として必須)
finance_list
⑤ 一目(転換線が基準線より上)
転換線 > 基準線(状態として必須)
finance_list
★ 変更点:クロス条件(直近N日)
直近 CROSS_LOOKBACK_DAYS=3 日以内に
MA5/MA25 の上抜け または
転換線/基準線 の上抜け
どちらか一方のクロスがあればOK(両方は不要)
finance_list
→ 「現実の動きに合いやすい(拾える銘柄が増えやすい)」設計
⑥ ATR(ボラの適正帯)
ATR14 を Close で割った “ATR比” が
ATR_MIN=1.5% 〜 ATR_MAX=3.5% の範囲内
finance_list
→ 低ボラすぎ(動かない)/ 高ボラすぎ(荒い)を除外
⑦ 流動性(売買代金)
直近20日平均の 売買代金(Close×Volume) が
MIN_TRADING_VALUE=1億円 以上
finance_list
→ すべり・板の薄さを避ける
⑧ 出来高増加(任意・現状OFF)
USE_VOLUME_SURGE_FILTER=False(使うなら “今日出来高 >= 20日平均×1.2”)
finance_list
C(監視枠)の条件(緩め:終値が基準線に近い)
終値が基準線の±near_width以内なら C として拾います
finance_list
near_width は
最低±0.3%(NEAR_KIJUN_WIDTH_MIN=0.003)
かつ(有効なら)銘柄ごとのATRに応じて拡張
near_width = max(0.3%, 0.4 * ATR比)
finance_list
C+ / C- の分割(監視優先度)
C+ は概ね「近い」+「上向き」+「中期上昇」+「最低限の流動性」
finance_list
基準線上向き(任意で必須化)
MA50>MA200 かつ Close>MA50(任意で必須化)
売買代金 0.8億円以上(CPLUS_MIN_TRADING_VALUE=80,000,000)
スコアリング(並び順を “強い順” にする仕組み)
USE_SCORING=True のため、A/B/C すべてに近い思想でスコアが付きます。
finance_list
主な加点要素:
基準線への近さ(近いほど高得点)
流動性(MIN_TRADING_VALUEの複数倍で満点)
ATR帯(ちょうど良いボラが高得点)
基準線の上向き度
直近クロス(MAか一目)
C+ にはボーナス(SCORE_CPLUS_BONUS)
finance_list
結果として intraday の監視対象選定もスコア順で優先されます。
finance_list
財務フィルタ(A/Bを分ける)
テクニカル強め候補のうち最大150件だけ(MAX_FUNDAMENTAL_CHECK=150)財務を見る設計です。
finance_list
A条件(全部満たす):
EPS > 0
PER ≤ 30
PBR ≤ 3
ROE ≥ 8%
finance_list
欠損や取得失敗、閾値外は B 扱い。
さらに重要:財務はTTL付きキャッシュで叩きすぎを防いでます(成功7日、失敗1時間)。
finance_list
日中(intraday)の BUY_ZONE 判定(“今買えるか”)
日中は「候補の中から、今の価格が買いゾーンにいるものだけ」表示します。
finance_list
ゾーン上限:zone_high = kijun*(1+near_width)
ゾーン下限:zone_low = kijun*(1-BUY_ZONE_BELOW_KIJUN_PCT)(デフォは 0.0=基準線割れは買わない)
finance_list
さらに条件(デフォでON):
日中安値がゾーン上限以下に入った(押した事実がある)
BUY_ZONE_REQUIRE_TOUCH=True
現在値がゾーン内
BUY_ZONE_REQUIRE_PRICE_IN_ZONE=True
finance_list
このBUY_ZONEを満たした上で、EODランクに応じて「今のA/B/C+/C-」として出します。
“出口(目安)” の計算(短期〜数ヶ月向け)
投資助言ではなくレポートの目安として、ATRで機械的に置いてます。
finance_list
損切:stop = kijun - 1.0*ATR
利確1:tp1 = entry + 1.0*ATR
利確2:tp2 = entry + 2.0*ATR
トレイル目安:MA25
finance_list
改善点(短期〜数ヶ月の“実運用”として効くもの)
1) C(監視枠)の情報を “いつ買いに行くか” へ寄せる
今は C を「終値が近い」で拾いますが、短期売買なら
“基準線に近い” だけでなく、押し目の再現性(例:過去N回の基準線タッチ後の勝率/平均上昇)
をスコアに混ぜると、C監視の質が上がります。
実装の方向性:
直近6〜12ヶ月で「基準線±near_widthに入った翌日〜5日後のリターン」を集計して
score += 勝率*係数 + 平均リターン*係数 のように加点。
2) “イベント・ギャップ耐性” フィルタ(短期では超重要)
短期〜数ヶ月は決算や大型イベントでギャップが出ます。
改善案:
決算予定日が近い銘柄を 除外 or スコア減点(特に翌営業日〜数日)
※これは外部データが必要ですが、運用の事故率が下がりやすいです。
3) ATR帯の「銘柄の性格」別チューニング
一律 1.5%〜3.5% は分かりやすい反面、
ディフェンシブ/大型は低めでも良い
グロースは高めでも許容したい
などが出ます。
改善案:
時価総額 or 値動き特性で ATR_MIN/MAX を可変にする
例:大型(時価総額上位)は 1.0〜2.8%、中小は 1.5〜4.0%
4) クロス判定の “ノイズ耐性” を上げる
直近3日以内クロスは機動力が高い反面、ダマシも増えます。
改善案(どれか1つでも効きます):
クロスに 出来高条件(現状OFFの出来高フィルタをクロス時だけON)
あるいはクロス後に 終値がMA25を上回っているなど “位置” 条件を追加
5) 財務フィルタの扱い(短期売買としての最適化)
短期売買では「PER/PBR/ROE」よりも
赤字(EPS<=0)回避
時価総額・流動性
需給(出来高・トレンド)
が効きやすいことも多いです。
改善案:
A/B を “財務” ではなく “需給・安定性” に寄せる選択肢
例:EPSは必須(赤字回避)だけ残し、PER/PBR/ROEはスコア加点へ移行
→ 「良い銘柄がBに落ちて監視優先が下がる」を減らせます。
6) スコアと表示ソートの一貫性
今、スコアは計算している一方で、EODのA/B表示は「乖離→流動性」でソートしています。
finance_list
改善案:
表示もスコア順を基本にすると、スコアリングの価値が最大化します。
例:上位20件はスコア順、その次は乖離順…などでもOK
7) 小さなバグ/品質(気づいた点)
EODレポートのA行で ROE...% が 2回出力されています(同じ文字列が重複)。
finance_list
→ ログ/通知が見づらくなるので1回にすると良いです。
いちばん効きやすい調整つまみ(実運用向け)
監視数が多すぎる → MIN_TRADING_VALUE を上げる / CPLUS_MIN_TRADING_VALUE を上げる
“押しが浅い”銘柄が多い → TOUCH_ABOVE_KIJUN_PCT を 0.0 に近づける(より深く押すの必須化)
買いのタイミングが遅い → BUY_ZONE_REQUIRE_TOUCH を残しつつ、BUY_ZONE_BELOW_KIJUN_PCT を 0.1〜0.3% だけ許容(ただし事故も増える)
ダマシが多い → CROSS_LOOKBACK_DAYS を 2 に縮める or 出来高条件をクロス時だけ足す
必要なら、あなたの「運用スタイル」に合わせて、次のどれかに寄せた **具体的な推奨パラメータセット(A案/B案/C案)**も作れます:
デイトレ寄り(1〜5日)
スイング(1〜6週)
2〜6ヶ月(中期寄り)
ただ、質問の範囲で結論を言うと、このコードはすでに
“上昇トレンド中の基準線押し目” を、流動性とボラで現実運用に耐える形に寄せたスクリーナーになっています。
以下は、いただいた finance_list.py の「抽出条件(A/B/C)」を 判定順に できるだけ噛み砕いて説明し、そのうえで 短期〜数ヶ月運用で効きやすい改善点 を挙げます。
finance_list
(※投資助言ではなく、条件設計・運用設計の解説です)
1) このスクリプトがやっていること(全体像)
このスクリプトは 2段構え です。
finance_list
EOD(夜):東証プライム全銘柄の「前日終値まで」の日足(1年)で
A/B(買い候補) と C(監視候補) を作り、スナップショット(pkl)保存
intraday(日中):そのスナップショットから「重要そうな銘柄だけ」最大300件を選び
1分足等で 現在値・日中安値 を取り、BUY_ZONE に入ったか を再判定して出力
2) まず前処理(ユニバース&価格フィルタ)
ユニバース
get_ticker_list() で 東証プライム銘柄 を取得(想定)
finance_list
価格レンジ
EODスナップショット作成時、まず “値がさ過ぎ/安過ぎ” を落とします。
finance_list
500円〜10,000円(MIN_PRICE=500, PRICE_LIMIT=10000)
ここで落とした残りに対して、1年分日足を取得して本判定へ
3) 使っている指標(ざっくり)
EOD判定で各銘柄について以下を計算しています。
finance_list
一目均衡表
基準線 kijun:過去26日高値/安値の中間
転換線 tenkan:過去9日高値/安値の中間
移動平均:MA5 / MA25 / MA50 / MA200
ATR14(14日平均 True Range)
流動性:売買代金(Close×Volume)の20日平均
4) “基準線近接幅” の考え方(超重要)
「基準線にどれくらい近いか」の判定幅を銘柄ごとに可変にしています。
finance_list
最低幅:±0.3%(NEAR_KIJUN_WIDTH_MIN=0.003)
さらに ATR比に連動(near_width = max(0.3%, 0.4 × ATR/Close))
つまり、ボラが大きい銘柄ほど「近接とみなす幅」も広がります。
5) ランク別の抽出条件(EOD時点)
C(監視):終値が基準線の近く
まず “監視候補C” を広めに拾います。
finance_list
終値が基準線±near_width以内
abs(Close - Kijun) <= Kijun * near_width
そして C を C+ / C- の2段階 にしています。
finance_list
C+(監視強):
基準線が上向き(直近5日で上昇)
中期上昇トレンド(MA50>MA200 かつ Close>MA50)
流動性(売買代金20日平均)0.8億円以上(CPLUS_MIN_TRADING_VALUE)
それ以外は C-(監視弱)
C は「買う」ではなく、押し目になり得る場所に来たら見る枠です。
A/B(買い候補の母集団):押し目+上昇トレンド+上昇シグナル+適正ボラ+流動性
A/B になる前に、まず “テクニカル強め候補” を作っています。条件はかなり明確です。
finance_list
押し目の形(戻し)
日中に基準線付近まで押したこと(EODでは当日安値で代用)
REQUIRE_INTRADAY_TOUCH=True
判定:Low <= Kijun*(1+0.1%)(TOUCH_ABOVE_KIJUN_PCT=0.001)
終値は基準線以上に戻す
Close >= Kijun(REQUIRE_CLOSE_ABOVE_KIJUN=True)
さらに、終値が上に離れすぎてたら除外
Close <= Kijun*(1+near_width)(上に伸び切ってる銘柄を弾く)
基準線が上向き(直近5日)
Kijun[-1] > Kijun[-6]
中期トレンド(大枠が上昇)
MA50 > MA200 かつ Close > MA50
短期トレンド(短期が優勢)
MA5 > MA25(状態として必須)
一目の状態
Tenkan > Kijun(状態として必須)
直近クロス(上昇の合図)
「どっちか一方のクロスでOK」にしています(改善点B)。
finance_list
MA5 が MA25 を上抜け または
転換線が基準線を上抜け
しかも 直近3営業日以内(CROSS_LOOKBACK_DAYS=3)
ボラティリティ帯(ATR比)
ATR/Close が 1.5%〜3.5% の範囲(ATR_MIN=0.015, ATR_MAX=0.035)
低すぎる(動かない)銘柄/高すぎる(荒すぎる)銘柄を除外
流動性(売買代金)
売買代金(Close×Volume)の 20日平均が1億円以上(MIN_TRADING_VALUE=100_000_000)
ここまで通ったものが “テク強候補” で、次に財務で A/B に分けます。
A と B の分岐(簡易財務フィルタ)
Aは「テクニカル+財務もOK」、Bは「テクはOKだが財務が弱い/不明」です。
finance_list
A(財務OK):
EPS > 0
PER ≤ 30
PBR ≤ 3
ROE ≥ 8%
B(財務弱/情報不足):
上記のどれかが欠損(yfinanceで取れない)
または基準外
※重いので財務チェックは最大150件まで(スコア上位から)に制限し、さらに TTL付きキャッシュ(成功7日/失敗1時間)で .info 連打を避けています。
finance_list
6) intraday の「買いゾーン(BUY_ZONE)」判定
日中は、EODで作った kijun/near_width を使い、現在値が “買いゾーン” かを判定します。
finance_list
上側:zone_high = kijun*(1+near_width)
下側:zone_low = kijun*(1 - BUY_ZONE_BELOW_KIJUN_PCT)(デフォ0%なので 基準線未満は買わない)
さらに2条件を要求:
finance_list
日中安値が zone_high 以下に入った(押した)(BUY_ZONE_REQUIRE_TOUCH=True)
現在値が zone 内にいる(BUY_ZONE_REQUIRE_PRICE_IN_ZONE=True)
BUY_ZONE を満たした銘柄だけを A/B/C+/C- として表示します(ゾーン外は OUT 扱い)。
7) 参考「出口」(短期〜数ヶ月向けの目安)
“投資助言ではなくレポート用の目安” として、ATRベースの出口を併記しています。
finance_list
損切り:基準線 − 1×ATR
利確1:エントリー + 1×ATR
利確2:エントリー + 2×ATR
トレイル:MA25(ある場合)
改善点(短期〜数ヶ月で効きやすい順)
すでに「キャッシュTTL」「C+/C-」「スコア」「クロス条件緩和」「出口目安」など良い改善が入っています。
finance_list
その上で、次のあたりが “成績と運用の安定” に効きやすいです。
A) 押し目判定の整合性を上げる(誤差/取りこぼしを減らす)
現状:日中に押したかどうかの判定が Low <= Kijun*(1+0.1%) で固定です。
finance_list
提案:ここも near_width と整合させると銘柄特性に合います。
例:Low <= Kijun*(1+near_width) を採用(または min(near_width, 0.3% など))
ボラが大きい銘柄で「押したのにtouch扱いにならず落ちる」を減らせます
B) 株式分割などの影響(指標の歪み)対策
yf.download(..., auto_adjust=False) なので、分割/併合が入ると移動平均やATRが歪むことがあります。
finance_list
案:テクニカル計算だけでも auto_adjust=True を検討
(もしくは Adj Close ベースで計算するなど)
C) “相場環境フィルタ” を追加(短期は特に効く)
短期〜数ヶ月は、個別の良い形でも地合いで潰れやすいです。
TOPIXや日経平均などで
例:指数が MA50>MA200 の時だけ A/B を採用
もしくは指数が下向きならスコアを減点
といった レジーム(相場環境)判定 を入れると、無駄打ちが減りやすいです。
D) 同じ“似た銘柄”に偏るのを抑える(運用上の改善)
スコア順だと、同業種がずらっと並ぶことがあります。
セクター(業種)情報を持てるなら、上位N件の中で業種上限を付ける
もしくは相関が高い銘柄を同時に取りすぎない
→ リスク分散と実運用が楽になります
E) スコアを「並び替え」だけでなく「足切り」にも使う
今はスコアは主に順位付け用途です。
finance_list
例:A/Bは score >= x の足切りを入れる
あるいは「dist(近さ)」が良くても流動性が弱い等を総合で落とせる
→ 候補が多すぎる日でも安定します
F) 小さな不具合/読みやすさ
運用品質には直接影響しないですが、直しておくと安心です。
finance_list
EODレポートで ROE... が 二重に出力されてます(文字列結合の重複)
intraday の c_now が一度作った後に同じ式で作り直されてます(動くけど冗長)
必要なら、あなたの運用イメージ(例:Aだけ買う / A+Bも買う / C+はアラートだけ、最大保有数、損切り幅の好み)を前提に、
この条件群を「短期(数日〜数週)寄り」or「数ヶ月スイング寄り」に最適化する具体案(閾値の推奨レンジや、どこを緩める/締めるか)まで落として提案できます。
以下は、添付の finance_list.py が「どんな条件で短期〜数ヶ月の売買候補を抽出しているか」を 条件ごとに分解して説明し、あわせて 改善ポイント(ロジック面/データ面/実装面) を具体的に挙げたものです。
finance_list
1) このスクリプトの全体像(EODスナップショット+場中監視)
このコードは大きく2段構成です。
finance_list
EOD(夜):東証プライム全銘柄(get_ticker_list())を対象に
日足1年分をまとめて取得 → 指標計算 → 条件で絞る → A/B/C(+C+/C-) を作ってスナップショット保存
intraday(場中):スナップショットに入った銘柄だけを対象に
現在値(1d+1m)を取得 → BUY_ZONE 判定 → その時点の価格で A/B/C を再表示
2) 対象ユニバースと前処理
対象銘柄
get_ticker_list() で得た 東証プライム銘柄(想定) が母集団です。
finance_list
価格レンジでプレフィルタ(最初の絞り込み)
EODスナップショット構築の最初に、直近日足(2日分)から「現在値相当」を取って価格レンジで絞ります。
finance_list
上限:PRICE_LIMIT = 10,000円
下限:MIN_PRICE = 500円
意図としては、
「極端な低位株(値動き・板・分割などでノイズが多い)を避ける」「値嵩すぎる銘柄も除く」
というタイプのスクリーニングです。
finance_list
日足取得
価格レンジ通過銘柄について 日足1年(period="1y", interval="1d") をチャンクで取得します。
finance_list
その後、各銘柄は 終値データが200本以上 ないとスキップされます(MA200計算のため)。
finance_list
→ 上場直後の銘柄などは対象外になりやすいです。
3) 計算している指標(スクリーニングの材料)
各銘柄について最低限これらを計算しています。
finance_list
一目均衡表(線だけ)
基準線(Kijun) = (26日高値の最大 + 26日安値の最小) / 2
転換線(Tenkan) = (9日高値の最大 + 9日安値の最小) / 2
finance_list
※雲(先行スパン)や遅行スパンは使っていません(ここは改善余地あり)。
移動平均(SMA)
MA5 / MA25 / MA50 / MA200
finance_list
ATR(14日)
TR = max(High-Low, |High-前日終値|, |Low-前日終値|)
ATR14 = TR の14日平均
finance_list
流動性(売買代金)
「売買代金」を Close * Volume として作り、直近20日平均 を使います。
finance_list
(※厳密には「約定代金」そのものではないですが、近似としてよく使われる形です)
4) “近接幅(押し目の許容レンジ)” の決め方
このコードの肝は 「基準線付近への押し目」 を中心にした抽出です。
その“付近”を銘柄ごとに可変にしているのが near_width です。
finance_list
near_width の定義
最低幅:NEAR_KIJUN_WIDTH_MIN = 0.003(±0.3%)
可変幅:near_width = max(0.3%, NEAR_KIJUN_ATR_MULT * (ATR/Close))
NEAR_KIJUN_ATR_MULT = 0.4
finance_list
つまり、ATRが大きい(ボラが高い)銘柄ほど “近接扱い” の幅が広がる設計です。 さらに、A/B(テクニカル強め)候補は ATR比が 1.5%~3.5% に限定されるので、
near_width も概ね次の範囲に収まります:
ATR/Close=1.5% → near_width ≈ 0.4×1.5% = 0.6%
ATR/Close=3.5% → near_width ≈ 0.4×3.5% = 1.4%
このあたりは「短期〜数ヶ月」向けの押し目許容としては割と妥当なレンジになっています。
finance_list
5) C(監視)銘柄の抽出条件(C+/C-)
C(監視)の基本条件
前日終値が基準線に近いだけで拾う、フィルタ緩め枠です。
finance_list
条件:abs(Close - Kijun) <= Kijun * near_width
→ 終値が「基準線±near_width」の中なら C です。
ここは A/B よりかなり緩いので、
「A/Bほど条件が揃ってないが、押し目の候補として目を付けておく」
という用途になっています。
finance_list
C+ / C- の2段階(監視の強弱)
ENABLE_C_TIERING = True のため、C枠は C+ と C- に分かれます。
finance_list
C+(監視強)になる条件(全部満たす必要あり)
基準線が上向き(直近5日で上昇)
中期上昇トレンド(MA50>MA200 かつ Close>MA50)
流動性(20日平均売買代金)>= CPLUS_MIN_TRADING_VALUE = 80,000,000
finance_list
満たさないものは C-(監視弱)です。
6) A/B(テクニカル強め)候補の抽出条件
このスクリプトの「本命抽出」はここです。
条件はかなり明確に段階化されていて、落ちた理由もカウントしています。
finance_list
① 押し目→戻し(基準線タッチと反発)
日中安値が基準線近辺まで押すことを要求
REQUIRE_INTRADAY_TOUCH = True のとき
判定:Low <= Kijun * (1 + 0.001)(+0.1% までを “触れた” 扱い)
finance_list
引けで基準線以上に戻すことを要求
REQUIRE_CLOSE_ABOVE_KIJUN = True のとき
判定:Close >= Kijun
finance_list
さらに「戻しすぎ(高い位置)は除外」
判定:Close <= Kijun * (1 + near_width)
finance_list
→ まとめると、終値は 基準線以上〜(基準線+near_width)以下 に収まっている必要があり、
「基準線を支持線として押して戻した直後」を狙う形になっています。
② 基準線が上向き(トレンドの向き)
判定:Kijun(t) > Kijun(t-5)(直近5営業日で上昇)
finance_list
③ 中期トレンド(大局の上昇)
判定:MA50 > MA200 かつ Close > MA50
finance_list
→ 「上昇トレンドの中の押し目」だけを狙っているのがはっきり出ています。
④ 短期トレンド(押し目後も弱くなりすぎてない)
判定:MA5 > MA25
finance_list
⑤ 一目の状態(短期の勢い)
判定:Tenkan > Kijun
finance_list
⑥ 直近の上抜けイベント(3営業日以内)
CROSS_LOOKBACK_DAYS = 3 の範囲で
MA or 一目のどちらかが直近でゴールデンクロスしている必要があります。
finance_list
MAクロス:MA5 が MA25 を上抜け
一目クロス:Tenkan が Kijun を上抜け
条件:どちらか一方が直近3日以内ならOK
finance_list
ここは「モメンタムが出始めた初動」を狙う発想です。
一方で “クロスから数日〜数週間経った押し目” は除外されやすいので、スタイルが出るポイントでもあります。
⑦ ATR比(ボラの範囲)
ATR比 = ATR14 / Close
条件:0.015 ~ 0.035(= 1.5%~3.5%)
finance_list
→ ボラが低すぎる銘柄(動かない)と、高すぎる銘柄(荒すぎる)を排除。
⑧ 流動性(売買代金)
直近20日平均 Close*Volume が
MIN_TRADING_VALUE = 100,000,000(=1億円)以上
finance_list
(任意)出来高増加フィルタ
USE_VOLUME_SURGE_FILTER=False なので今はOFFですが、ONにすると
今日出来高 >= 20日平均 * 1.2 でないと落とす
finance_list
7) A / B の分岐(簡易財務フィルタ)
テクニカル条件を全部満たした銘柄(内部的に “T”)に対して、
yfinance.Ticker(t).info を使って財務フィルタをかけます。
finance_list
A(財務OK)
以下を全部満たす必要があります:
EPS(trailingEps)> 0
PER(trailingPE)<= 30
PBR(priceToBook)<= 3
ROE(returnOnEquity)>= 0.08(8%)
finance_list
B(財務弱め/不明)
上記のどれかが欠損(取得できない)→ B
閾値を外れる → B
finance_list
重要:財務チェックは上限150銘柄
MAX_FUNDAMENTAL_CHECK = 150 があるので、
テクニカル合格が大量に出た日に 上位150件しか財務判定されず、残りはそもそも捨てられます。
finance_list
(意図は処理負荷軽減ですが、「抜け」を作る仕様なので、ここは理解しておくべき点です)
8) スコア(優先度)の意味
ランキング用に _calc_score() があり、ざっくり以下で加点されます。
finance_list
基準線に近いほど高得点(dist_norm が小さいほど)
流動性が高いほど高得点
ATR比が “適度な中間” に近いほど高得点
基準線の上向きが強いほど高得点
直近クロス(MA/一目)の有無で加点
C+ はボーナス加点
finance_list
このスコアは、
財務チェック対象150件に絞るときの優先付け
intradayで監視対象を最大300件に絞るときの優先付け
に効いています。
finance_list
9) intraday(場中)の BUY_ZONE 判定
場中は、スナップショットの A/B/C+/C- を最大300件取り出し、現在値を取りに行きます。
finance_list
取得している価格
fetch_live_quotes() は2段階で取得します。
finance_list
まず period="2d", interval="1d" で prev_close と日足の値を確保
可能なら period="1d", interval="1m" で price/day_low/day_high を上書き
(コメントでは /v7/finance/quote と書いてありますが、実装は yfinance の download 経由です)
BUY_ZONE の定義(デフォルト設定)
zone_high = Kijun * (1 + near_width)
zone_low = Kijun * (1 - BUY_ZONE_BELOW_KIJUN_PCT)
デフォルト BUY_ZONE_BELOW_KIJUN_PCT = 0.0 なので zone_low = Kijun
finance_list
そして、
BUY_ZONE_REQUIRE_PRICE_IN_ZONE = True
→ 現在値が zone_low~zone_high の中にいることが必須
BUY_ZONE_REQUIRE_TOUCH = True
→ day_low が zone_high 以下に入ったことが必須(ただし下で説明)
finance_list
注意(仕様上の“ほぼ冗長”ポイント)
BUY_ZONE_REQUIRE_PRICE_IN_ZONE=True のままだと、
現在値が zone 内にあるなら day_low は通常それ以下なので、
touch条件は実質ほぼ常に満たされやすいです(day_low が正しく当日値なら)。
finance_list
ただし、
1mが取れず1dの値が古い/ズレる
day_low が欠損
などがあると touch が効いてきます。
改善ポイント(実運用で効きやすい順)
ここからが「改善点」です。コードの意図を崩さずに、精度・運用性・保守性を上げる観点で挙げます。
finance_list
A) ロジック面(抽出の“質”の改善)
1) 「直近3日クロス必須」は取りこぼしが増えやすい
いまは「押し目+上昇トレンド」でも、クロスが3日より前だと落ちます。
finance_list
スタイルとして初動狙いなら良いですが、
数週間続く上昇トレンド中の“押し目2回目・3回目”
押し目後に再加速する局面
を狙うなら、例えば次のような緩和が候補です:
CROSS_LOOKBACK_DAYS を 3→5〜10 に
「クロスの発生」ではなく「fast>slow を維持している日数」でも良い
あるいは「MA5>MA25 かつ Tenkan>Kijun を維持」のみでクロス判定を外す(スコア加点要素に落とす)
2) 押し目判定を“当日だけ”に固定している
EOD判定が「当日の安値が基準線近辺まで押した→引けで戻した」という1日パターン固定です。
finance_list
実際の押し目は複数日に渡ることが多いので、例えば:
「過去N日で一度でも基準線近辺まで押して、その後基準線上に回復」
のようにすると候補が増えます(ただしノイズも増えるのでスコア/追加条件で抑える設計が良い)。
3) 一目は“線”だけなので、雲を使うとトレンド判定が安定
現状は Tenkan/Kijun の関係だけ見ています。
finance_list
短中期で一目を使うなら、典型的には
価格が雲の上
先行スパンが上向き/雲が陽転
などを入れると「地合いが弱いのに線だけで合格」を減らせます。
B) データ面(精度と再現性)
4) 分割・配当などの“調整”をどう扱うか
yf.download(... auto_adjust=False) なので、分割が入ると過去データに段差が残り、
MAやATR、基準線などが歪みやすいです。
finance_list
指標計算は auto_adjust=True(または Adj Close 系)を使う
ただし売買代金(Close*Volume)は実額が欲しい
→ 指標用(調整)と流動性用(非調整)を分けるのが実務的には一番きれいです
5) 休日実行時の asof_date 表示
休日にスナップショットを新規作成すると asof_date=today になりますが、
実際に取れている価格は前営業日までだったりします。
finance_list
改善案:
取得した日足の最新日付(close.index[-1])を “実データ日付” としてスナップショットに保存し、レポートでもそちらを表示する
(運用時の混乱が減ります)
C) 財務フィルタ面(日本株で起きがちな課題)
6) yfinance .info は欠損・ブレが出やすい(特に日本株)
現状は欠損=B扱いで、Aがかなり減りやすい設計です。
finance_list
改善案(方針別):
「欠損はB(現状維持)」で良いが、Bを“悪い”と誤解しないよう表示を工夫
例:B(情報不足) と B(割高/低ROE) を分ける
欠損が多い指標(ROEなど)はスコア要素に落とし、A判定はもう少し頑健な項目に絞る
(EPS>0、極端なPER/PBRを避ける、など)
7) 財務チェック150件上限による“見落とし”
MAX_FUNDAMENTAL_CHECK=150 で上位150件しか残らないので、
「テクニカル合格はしてるのに出てこない」日が出ます。
finance_list
改善案:
150件以降は “B(財務未チェック)” として残す(捨てない)
もしくは財務チェックをやめて A/B を別軸にする(短期売買なら合理的な場合も)
D) 実装・運用面(バグ、読みやすさ、レート制限)
8) レポートの小さなバグ/改善
render_eod_report() の A行で ROE が2回出力されています(文字列重複)。
finance_list
→ 表示の誤解を避けるため修正推奨
EODレポート側は C+ / C- の内訳を出していないので、せっかくの tiering が見えません。
finance_list
→ C枠の表示も C+ と C- を分けると運用しやすいです
9) 使っていない設定/変数がある(設計意図と実装がズレて見える)
例:
RATE_LIMIT_BREAK_AFTER_CONSECUTIVE_CHUNKS が定義のみで未使用
finance_list
SLEEP_BETWEEN_PRICE_CHUNKS_SEC があるのに time.sleep(2) がハードコード
finance_list
/v7/finance/quote を使うとコメントにあるが実装は yf.download
finance_list
make_yf_session を import しているが使っていない
finance_list
→ 「自分用スクリプト」でも、ここが整理されると保守性が上がり、パラメータ調整もしやすくなります。
10) レート制限対策は“あと一歩”で強くできる
_yf_download_with_retry() のバックオフは良いです。
finance_list
一方で、コメントにある “サーキットブレーカ” が未実装なので、例えば:
チャンク処理ごとに「429が連続した回数」を数え、一定回数で打ち切る
その時点で「どこまで取得できたか」を残して終了(または intraday は部分結果で出力)
にすると、場中の監視が止まっても原因が追いやすいです。
E) “改善の最短ルート”:検証の仕組みを足す
条件調整(ATRレンジ、near_width係数、クロス日数、売買代金閾値)は、
バックテストや簡易検証がないと「どれが効いたか」が曖昧になりがちです。
finance_list
おすすめは重いバックテストでなくてもよくて、例えば:
スナップショットに「翌日〜5日後の最大上昇率/最大下落率」を記録して集計
A/B/C+/C- ごとの分布を見る
reject理由上位の銘柄のサンプルを保存して、落としすぎ/拾いすぎを確認
だけでも、パラメータ調整の質が一気に上がります。
すぐ直せる「小さな修正」例(代表)
投資ロジックとは関係なく、まず直すと良いものです。
finance_list
ROEが2回出る表示の重複を削除
time.sleep(2) を SLEEP_BETWEEN_PRICE_CHUNKS_SEC に統一
C+ / C- の件数を EOD レポートに出す
コメント(/v7/finance/quote 等)と実装の整合を取る
未使用定数・未使用 import を整理
必要なら、あなたの運用スタイル(「初動だけ狙うのか/トレンド中の押し目も拾いたいのか」「監視できる銘柄数」「許容するATRや売買代金」)に合わせて、
CROSS_LOOKBACK_DAYS の扱い
押し目判定(当日限定→複数日窓)
BUY_ZONE の定義(基準線割れ許容、反発後の追い買い許容)
あたりを コードの差分レベルで具体化する案も提示できます。
実務で効く具体例8選(スクショ前提)
コードの理解・改善案の
回答結果を見ましたが、
高度なモデルは背景まで見て、
提案改善をしてくれてます。
高度なものは時間かかる
ただ制限もあるので、
難しいことや高度な問題の場合に
使用するなど、
モデルの使いどころが重要です。
メールの文章清書して
これは高度なものは必要ないですね。
では具体的にどういう使用用途があるか
見ていきましょう。
①文章作成
使う場面:メール作成・議事録作成
おすすめモデル:Instant・標準モデル
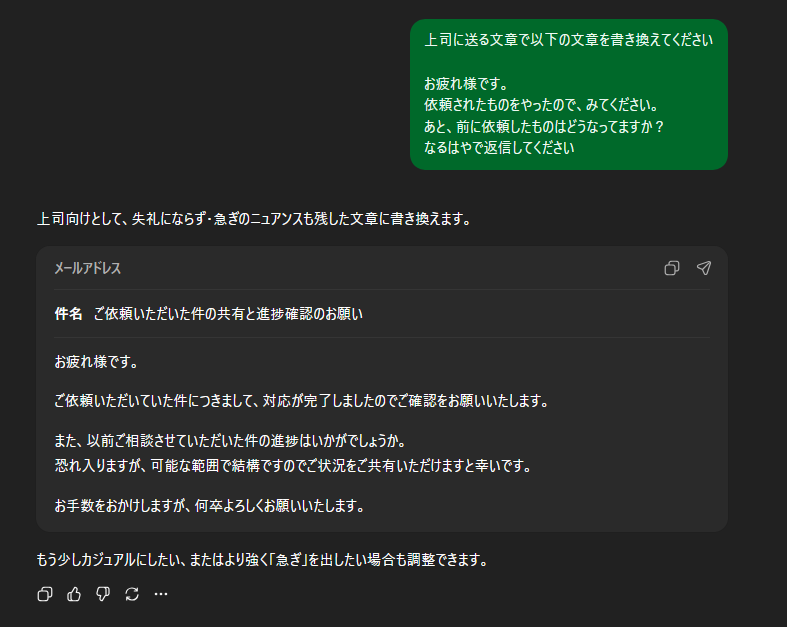
このように、誰宛になど明確にし
適当な言葉を羅列しても
綺麗に文章を作成してくれます。
また音声や会話ログを流し、
議事録作成と頼むと
議事録も作成してくれます。
②アイデア出し
使う場面:アイデア出し・壁打ち
おすすめモデル:標準モデル・Thinking
- 案出し(スクショ)
- ブログ案(スクショ)
- アンケート案(スクショ)
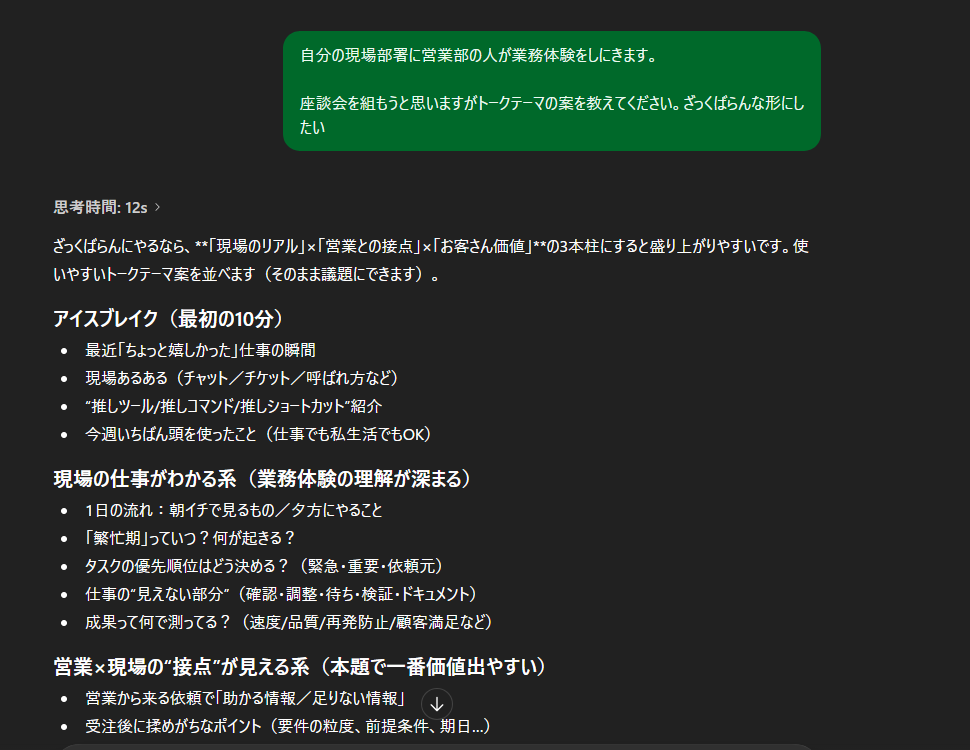

案出し
○○をしたいけどどうすれば?
などを伝えると、どうすればいいかを
順序立ててアイデアを教えてくれます。
それを元に組み立てれば
かなり時間の短縮です。
また、
ブログ文章・タイトル作成もお手の物。
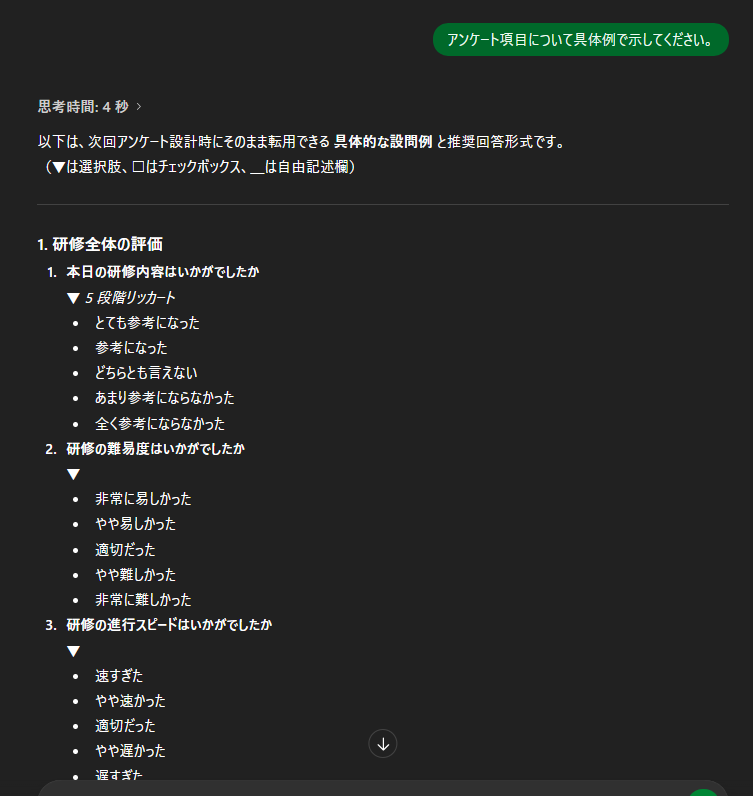
アンケート作成
やってること、やりたいことを伝え、
アンケート作成も可能であったり、
今のアンケートから
悩みや改善点を伝えることで、
さらに改善も可能になります。
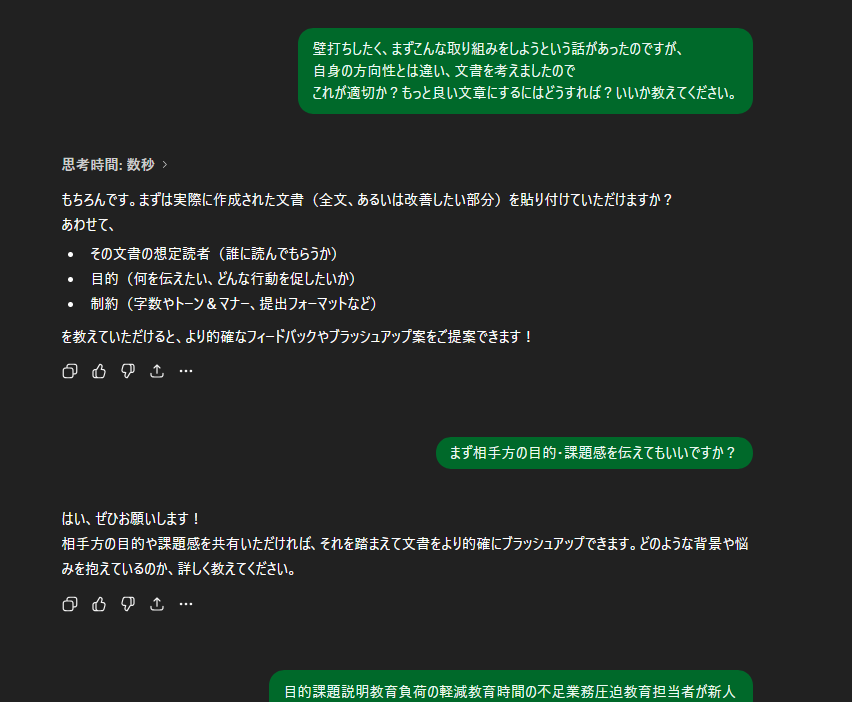
壁打ち
アイデアが湧かず、漠然としてるときは、
ChatGPTが良き相談になってくれます。
今回は教育関連で相談しました
- こういうこといわれてる
- こう思う
などの会話を繰り返すことで、
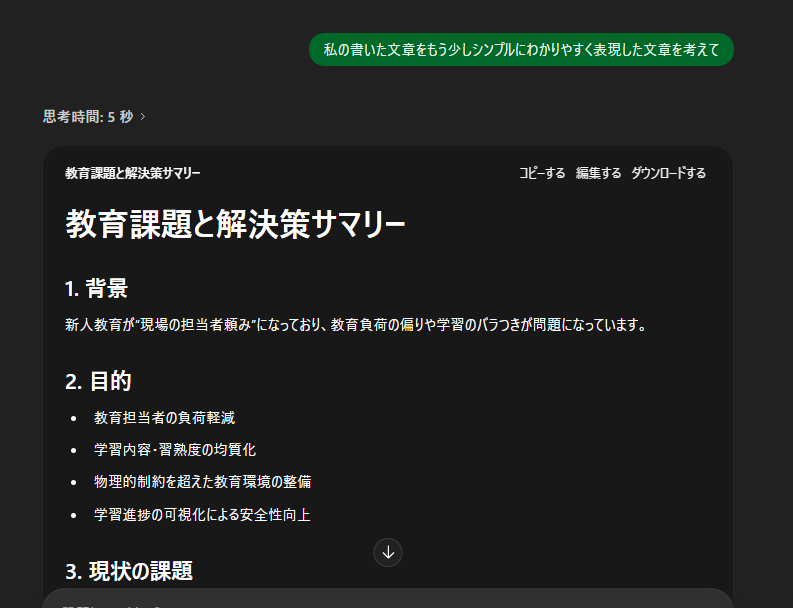
実現したいことを固めることができます。
最終的に
文章やサマリーを作成することも可能
③検索の代用
色んなページがあって
どれが正解なの?
商品の違いわからないな。
こういう悩みもChatGPTで解決です!
おすすめモデル:標準モデル・Thinking
疑問の検索
ケース①
純粋な疑問の検索


健康には
オリーブオイルだけで良くない?
その疑問を投げつけると、
比較しわかりやすく説明してくれました。
ワード検索→色んなページ確認
という面倒な作業短縮になります!
比較・おすすめ検索
ケース②
商品比較・おすすめ紹介
同じような商品あるな~?
違いは何?

PCの例で、スペックが似たようなもので
どう違うかよくわからない場合、
型番やモデル名を入力し
違いやおすすめを聞くと、
上図のように一覧やおすすめが出ます。
普段では、各商品ページの詳細確認して
違いを見ないとわからない
おすすめは何?
例えば、自分の悩みがあった時、
以下のような
悩み→商品おすすめを
伝えてください
詳しく比較したい場合、
Deep ResearchやProモデルを使用。
自分にあった商品提案がされ、
その後の対話により商品を絞り込めます。
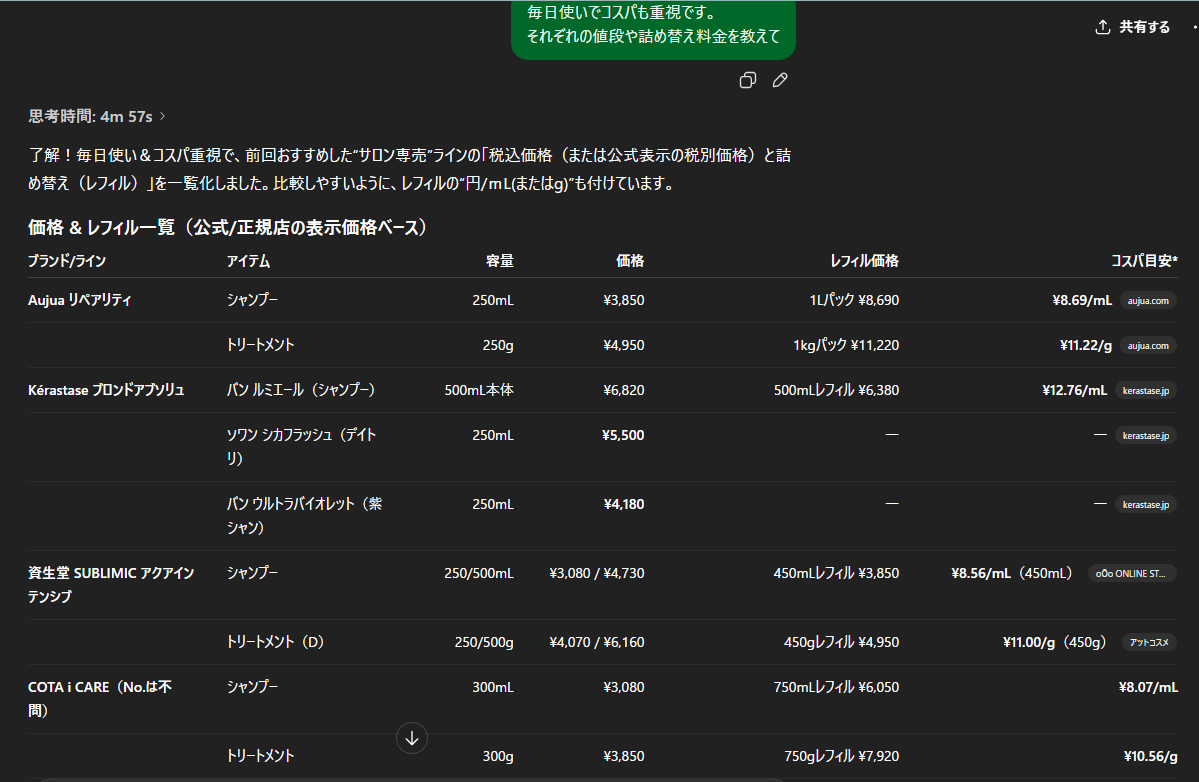

出てきた結果の料金調べたり
今使ってる成分を貼り付けるだけで、
効能が調べることも可能。
今までの検索では
悩みからの検索はできなかったので、
これもAIの強みです!
④予想
使う場面:予想を使う場面
おすすめモデル:Thinking・Pro
今回は
競馬・株価予想をしてみよう!
100%ではないものの、
学習させることで、精度を高めれるのか?
あくまで予想なので、
判断材料である旨は留意。
- 競馬予想(スクショ)
- 株式予想(スクショ)



こういう形で、
過去のデータから予想を出して、
未来を予測する回答もしてくれます。
ちなみに競馬では
過去10年の総合的な判断で
予想してもらってます。
ちなみに35レースを
予想家・無料予想と比べると
ChatGPT予想が
上位の点数を誇りました。
⑤分析
使う場面:各分析結果をまとめたい
(アンケート結果など)
おすすめモデル:Thinking・Pro
分析するのもかなり強力ツールです。
今回は
ある勉強会のアンケート結果から
まとめや改善策を聞いてみます
従来は、
アンケート結果を取り込み
(BIツール等)で
データ成型→集計→抽出→まとめ
などの作業を時間をかけて実施しました。
どのデータを使おうか
どの数値を計算しようか
時間がかかる。。
ChatGPTなら、
データ取り込み→完了
です!
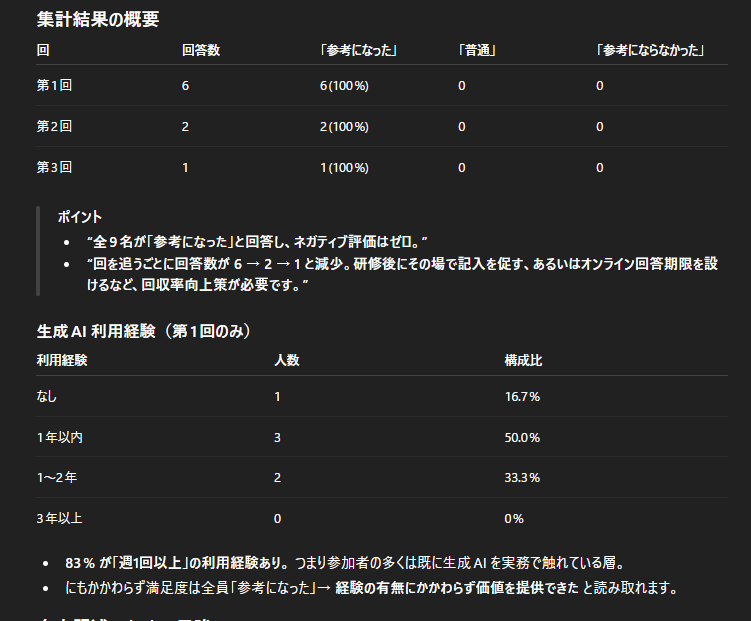
このように、
Forms結果をCSVで出力して、
それをChatGPTに張り付け、
プロンプト例:
添付したアンケート結果([ファイル名])を分析してください。
1. 背景: [例:新しくリリースしたWebサービスのユーザー満足度調査です]
2. 依頼事項例:
・全体の満足度の傾向を要約してください。
・満足度が高いユーザーと低いユーザーの決定的な違いを特定してください。
・[年代] 別に、[利用頻度] の違いが [満足度] にどう影響しているか分析してください。
・今後の具体的な改善アクションの提案。
- まずどういった背景なのか
- 何を知りたいのか?
- 何を詳しく見たいのか?
- 分析結果や改善点を含める
こういった形で投げるだけで、
すぐに修正や分析まとめ
+
改善点まですぐに出ます!
今までは
かなりの時間を要してたのが
すぐに纏めがでるので時間短縮
また自分の知らない分析手法も
出してくれるので、
必要なものを取捨選択して
データに基づいた改善に役立ちます!!
⑥画像認識+画像作成
画像からの検索・提案
使う場面:これどうなの?これなに?な時
おすすめモデル:Thinking
ケース①
ゲームの装備品が
いいかどうか判断してもらおう!
ということで原神の聖遺物スコアを
チェックしてもらいました!
聖遺物どれがいいかわからん
ネットで情報散見されるな。。

例はナヒーダのチェックです。
事前にどういうパーティーで使いたいか
今のセット画像を貼り付けてチェック!
結果どおり詳細に
チェックしてくれます!
+
どれを改善するかもお手の物
ケース②
今回は古い機器(ひかり電話)が
どういう構成になってるかを検索
これなに?
いまどういう状況?
みたいなケースがありますよね。
その際も写真撮って検索です!!

通常検索でもよくわかんない場合
あったりしますよね
そういう時は写真でなにこれ?
とかどうすれば?
と投げかけるだけで情報が出ます!
写真検索がかなり便利です!
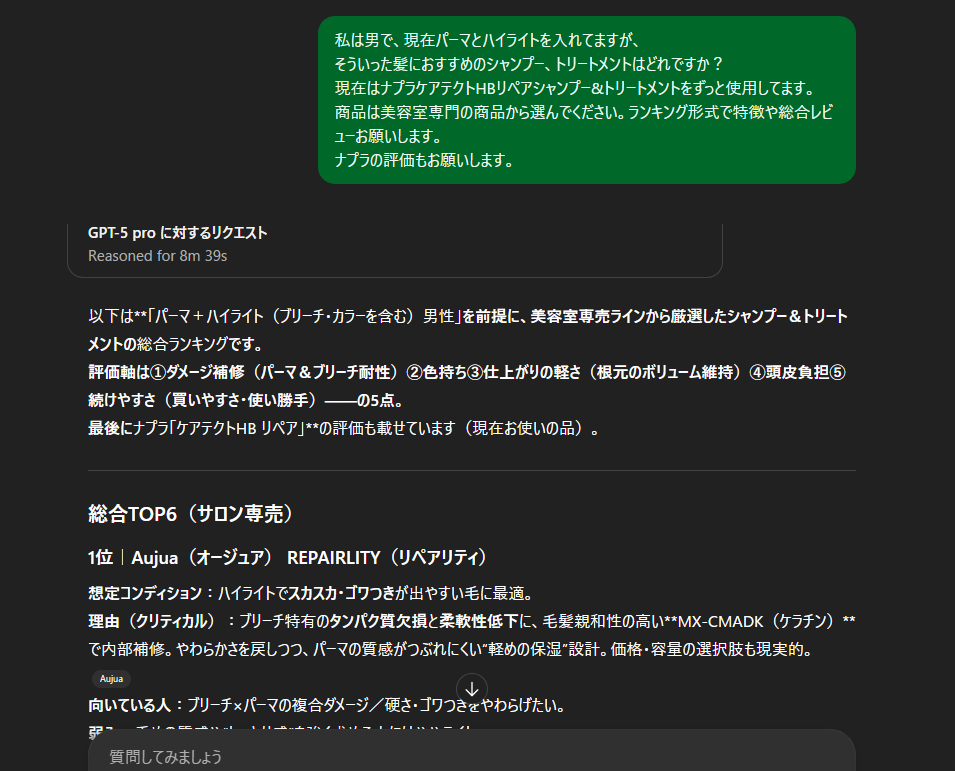
ケース③
髪の状態から
商品提案をしてもらいます
今までは文字のみの悩みがあっても、
文字で伝えるの困難な場合がありますね。
その時は写真撮っちゃえばいい!
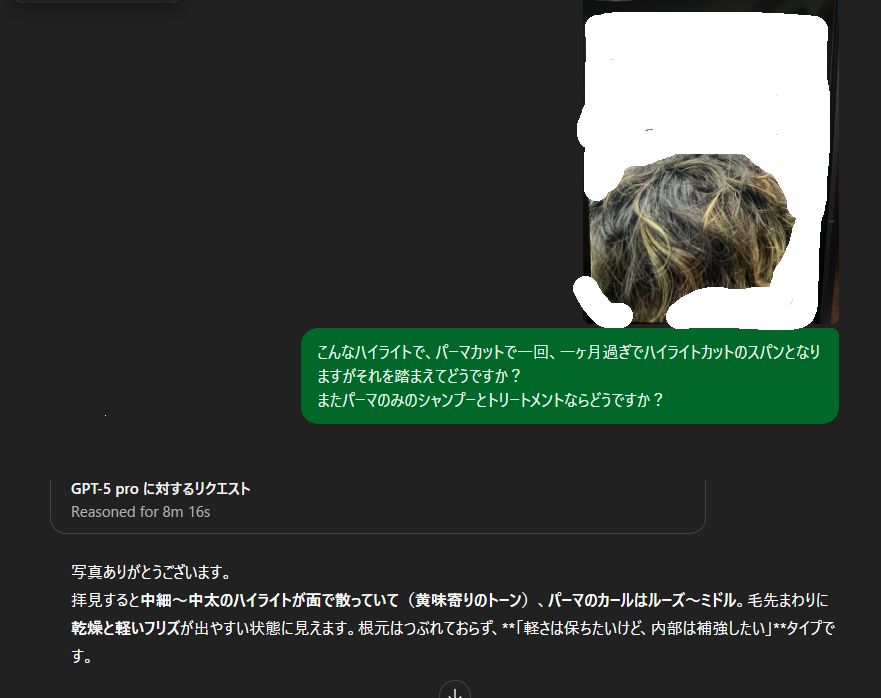

※今回はPro版使用
このように写真から見た感じで
商品提案をしてもらうと、
今の状態にあったものが提案
+
手入れまで提案してくれます!
ケース④
ふるさと納税って
いくらまでできるの?
源泉徴収をサイトに入力しての手間を
ChatGPTに投げてみました!
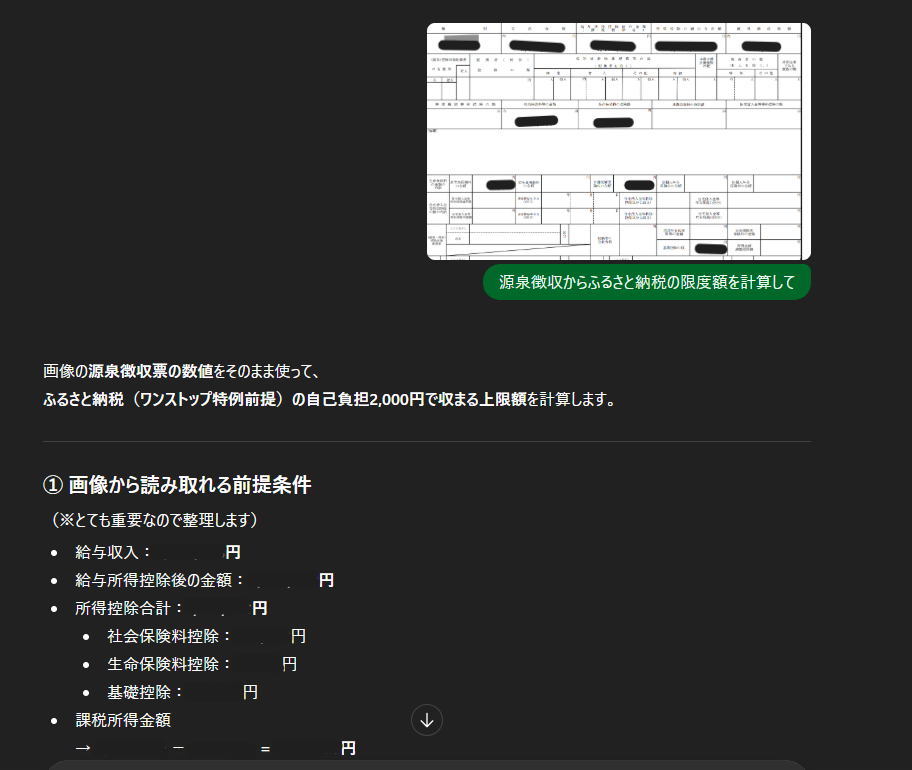
するといくらまで使えるかもが
パッとでるので便利です!
画像作成
使う場面:アイコンやアイキャッチ画像
作成したい
おすすめモデル:Thinking
生成AIは画像作成も簡単です!
従来は
書いたり・素材探したり
と労力も大変です。。
ChatGPTならすぐに作成されます。
- アイキャッチ画像(スクショ)
- アイコン画像(スクショ)

ちょっとカスタムしてますが、
どういうテーマの画像かを伝えると、
このようにアイキャッチやアイコン画像も
お手の物です!
画像に日本語入れる場合は
文字化けしたり、一部修正では
全体が変わったりするので、
文字は一部修正は
GoogleAI(nanobananaPro)が優秀
なので背景のみ作成後にCanvaなどで
文字入れ修正って流れがおすすめです。
⑦プログラミング
使う場面:アプリ作成・コード修正したい
おすすめモデル:Thinking・Pro
そもそも知らないと、
なにをどうしたらいいかも
わからないのが基本でした。
今では誰でも
アプリをつくれちゃう時代です。
やりたいことを提案
今回は競馬予想サイト集計を
アプリケーションとして実現させます。
| 従来 | 理想 | |
|---|---|---|
| ・エクセルで集計 ・手入力 ・当選率は単純 | → | ・WEB上で集計 ・半自動 ・予想数や順位による 勝率計算 |
実現したいことをまとめて、
一つづつ会話していきます。
結果
このように必要コード群が
パッと作成されます!
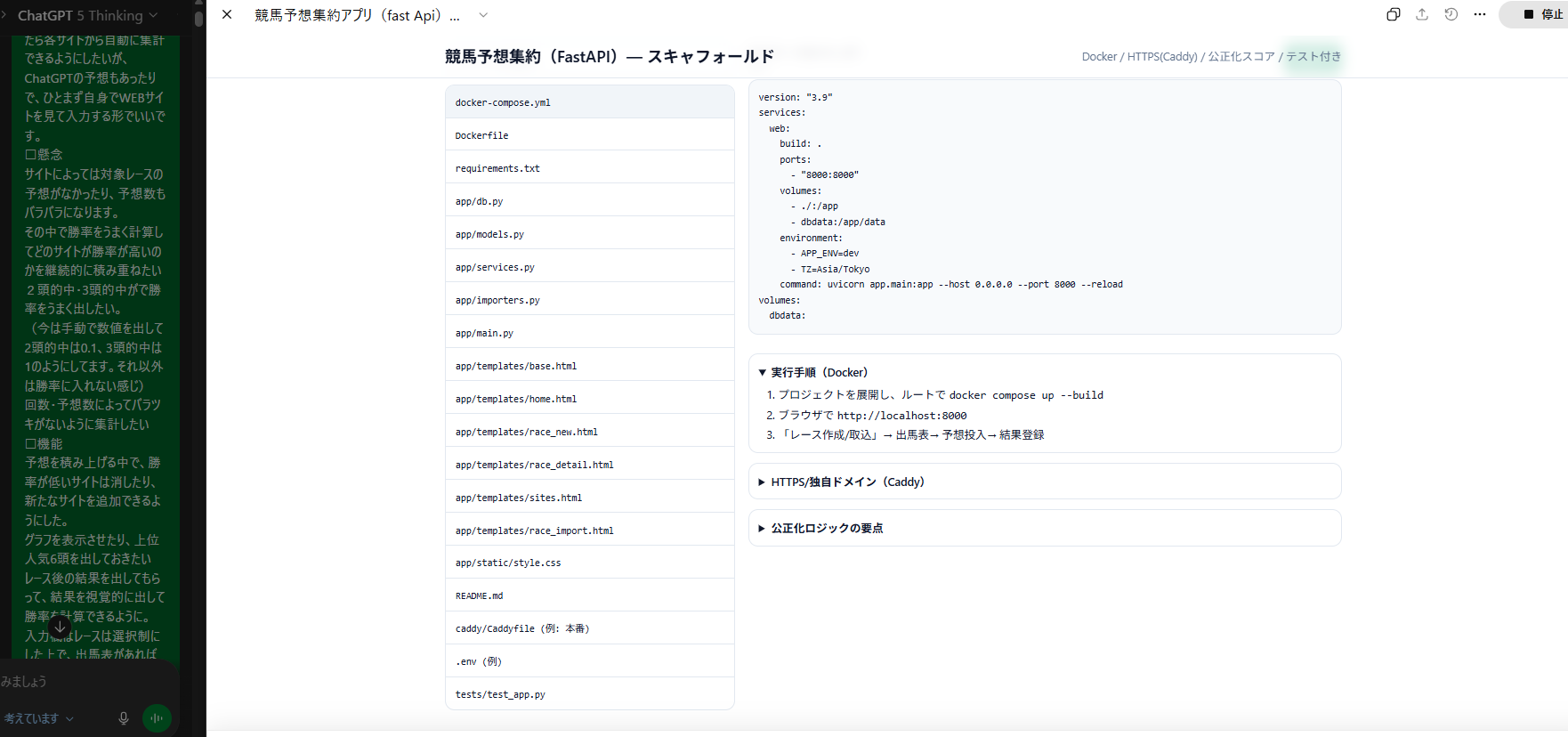
その後じゃあ実際の細かい手順も
会話によって提案されていくので
それを参考に実装していきます。
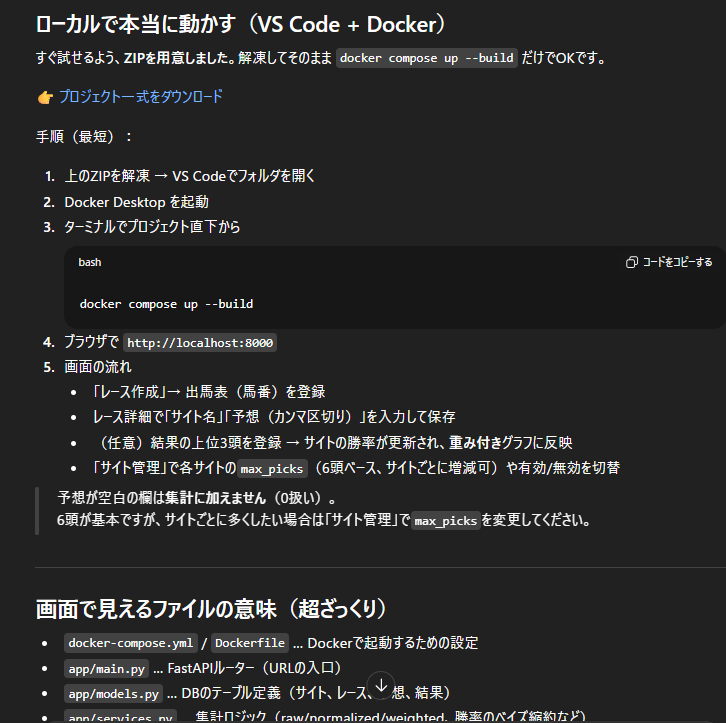
エラー修正
これでなんでもできるかな
と思っても、
結果だけで動く感じではないです。
またイメージしていたものと
違う場合もあります。
その辺りはここを○○になど対話を
重ねていきます。が!
出た結果がエラーになることも多々。。
その場合は、
エラー内容を渡して
理想に近づけていきます。
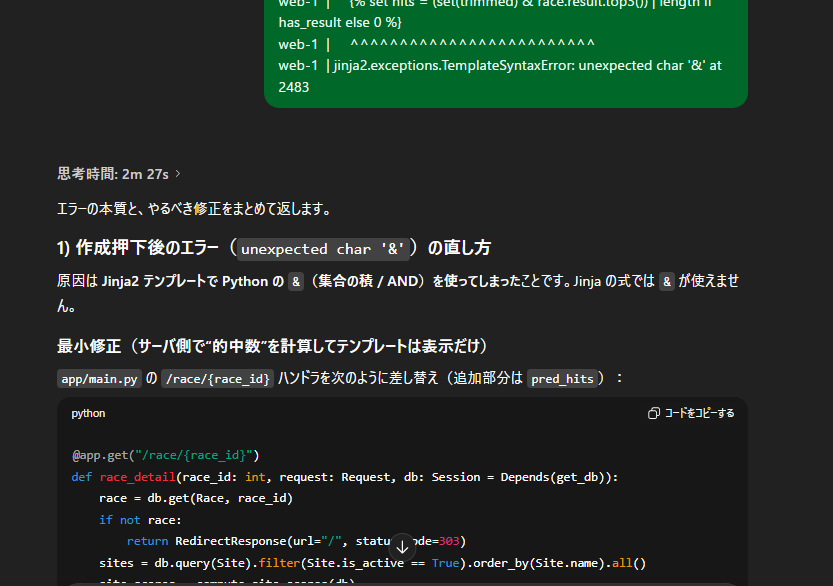
完成物の一例
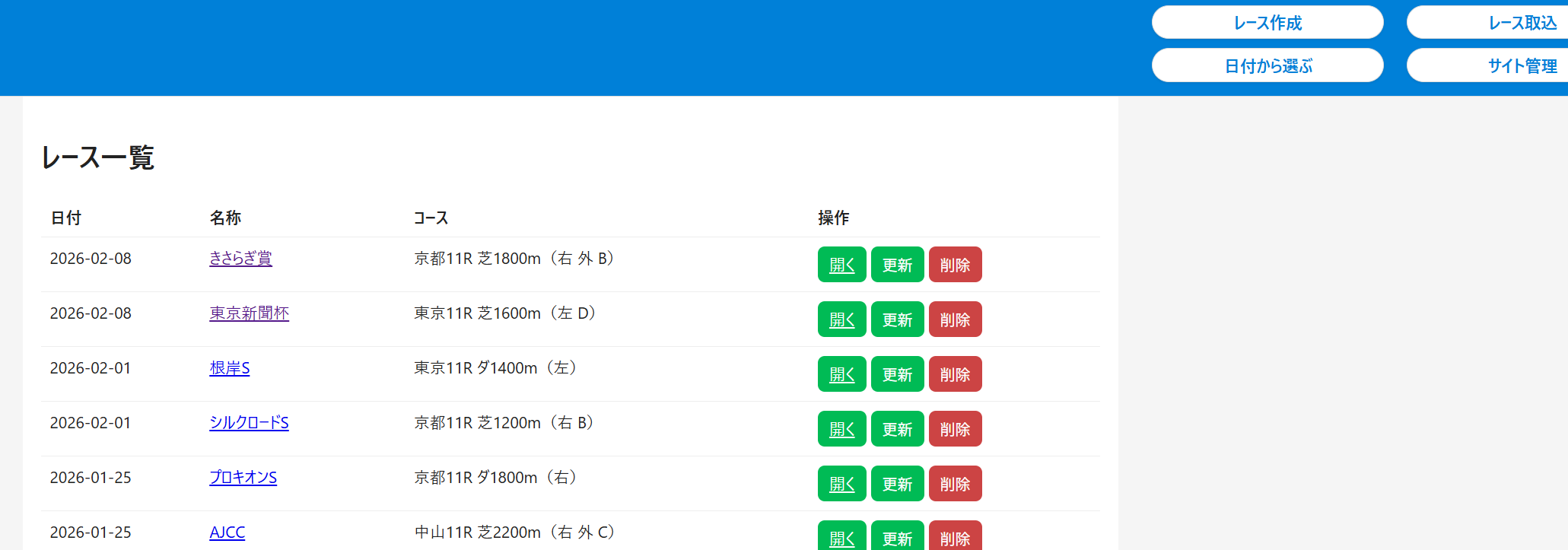

日付から自動でレース取り込みしたり
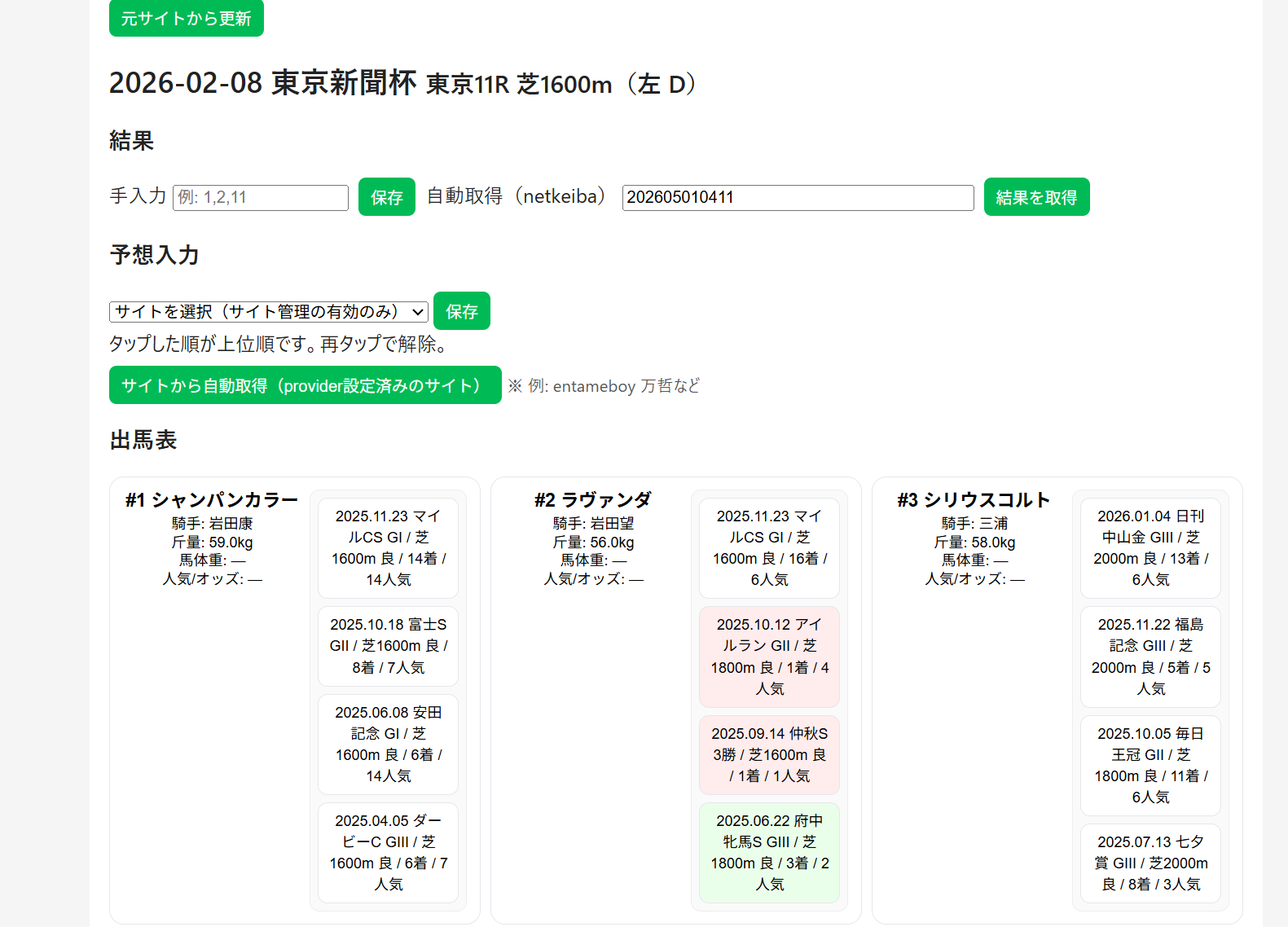
サイト予想をクリックして入力したり、
自動取り込みしたりしてます。
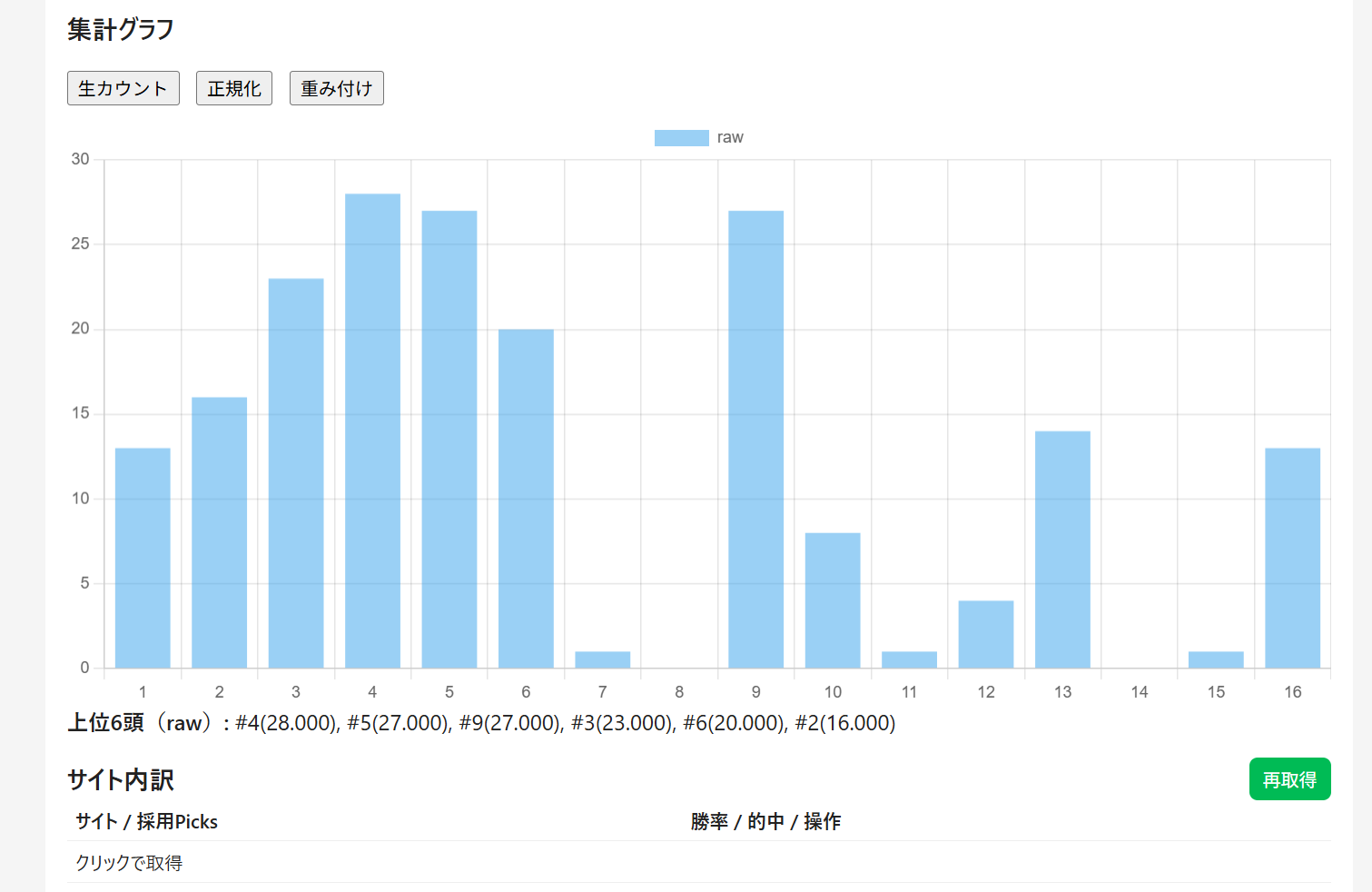
その結果を勝率を基に
グラフ化させたりもしてます。
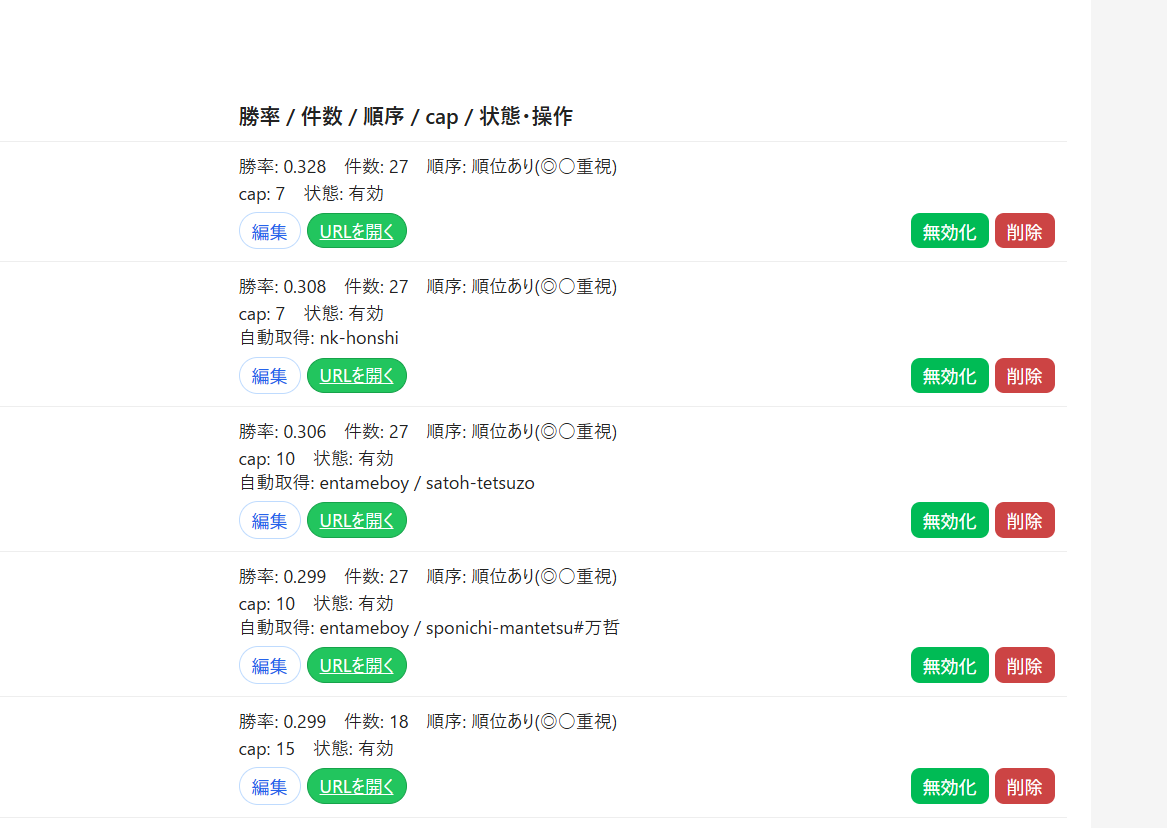
サイト管理上で、新規サイト追加や削除、
勝率までを計算させたりもしてます。
このように理想の形に
対話型で作成できます。
⑧実務で使う実用例集
提案書・企画書
使う場面:ゼロから作るのが重い/構成で悩む
おすすめモデル:Thinking(論点整理)
コピペ用プロンプト
あなたはB2Bの提案書作成が得意なコンサルです。
以下の条件で提案書の骨子を作ってください。
目的:意思決定者が「この方向で進めよう」と言える状態にする
出力:
- 章立て(H1/H2レベル)
- 各章の要点(3〜5行)
- 提案の差別化ポイント(3つ)
- リスクと対策(表)
- 想定QA(質問10個+回答案)
前提情報:
[商材/施策/背景/制約などを貼る]
ビジネスで使えるのは、
提案書や企画書づくりの土台です。
0から考えるよりも骨組みを作ることで、
時間短縮にも繋がります。
仕様書/手順書レビュー(曖昧表現・矛盾・未定義語の指摘)
使う場面:レビュー漏れが怖い、
品質を一定にしたい
おすすめモデル:Thinking
コピペ用プロンプト
以下の仕様(または手順書)をレビューしてください。
観点:
- 曖昧表現(例:「適宜」「可能な限り」など)の洗い出し
- 矛盾(前後で条件が食い違う等)
- 未定義語(用語集にない用語、境界条件がない項目)
- テスト観点(最低10個)
出力形式:指摘一覧の表(重要度:高/中/低、修正案つき)
--- 仕様 ---
[ここに貼る]
--- ここまで ---
手順修正でも使えますが、
1から作成することもできるので、
作成・レビューの
同時使用がおすすめです。
CSV分析 → 傾向 → 打ち手(グラフ+示唆)
使う場面:数字を見ても結論が出ない
/分析→示唆までつなげたい
おすすめモデル:Auto・Thinking
コピペ用プロンプト
このCSVを分析して、意思決定につながる形にしてください。
出力:
1) データ概要(欠損・外れ値・集計の前提)
2) 重要な傾向トップ3(グラフが適切ならグラフも)
3) 取るべきアクション案(優先度つきで5つ)
4) 追加で欲しいデータ(あれば)
前提:
- 目的:[例:解約率を下げたい/売上を伸ばしたい]
- 期間:[例:2025/10〜2025/12]
- 指標の定義:[わかる範囲で]
アンケート分析の欄でも
触れましたが、
それ以外にもエクセル等のデータ群を
渡すことで、
傾向から改善までをまとめてくれます。
障害対応・ログ解析の切り分け(仮説→検証手順→復旧案)
使う場面:ログはあるが、
どこから見ればいいか迷う
おすすめモデル:Thinking
コピペ用プロンプト
以下の事象について、切り分けを進めたいです。
あなたはSREとして、最短で原因に近づく手順を作ってください。
出力:
- 原因仮説(可能性順に5つ)
- 各仮説の確認手順(コマンド例・見るべきログ・期待される結果)
- まず最初の15分でやること(チェックリスト)
- 影響範囲の確認観点
- 恒久対策の方向性(3案)
--- 事象メモ/ログ ---
[ここに貼る]
--- ここまで ---
仮説付けもお手の物で、
自身が気づけないポイントも
発見できます。
それを基に発展できるので、
こういう形でも強みです。
コードレビュー(差分の意図/リスク/テスト観点を言語化)
使う場面:レビューの抜け漏れ防止、
PR説明を短時間で作る
おすすめモデル:Thinking
コピペ用プロンプト
以下のPR差分をレビューしてください。
出力:
1) 変更点の要約(3行)
2) 影響範囲(どこが壊れうるか)
3) リスク(高/中/低)と理由
4) テスト観点(最低10個、可能なら具体例)
5) リファクタ提案(任意)
--- diff / 変更内容 ---
[ここに貼る]
--- ここまで ---
初めの出力結果の違いでも見せましたが、
コードレビューも強みです。
漏れだけでなく差分もみれるので、
より効率的かつリスク分析できるので
使わないのは損です。
調査まとめ(出典・反証・次アクションまで)
使う場面:調べ物が散らかる
/社内説明用に根拠が必要
おすすめモデル:ProまたはThinking
※Deep researchの使用
コピペ用プロンプト
テーマ:[調べたいテーマ]
目的:社内説明のため、結論と根拠を短時間で揃える
要件:
- 結論を先に(3行)
- 根拠(出典を明記)
- 反対意見・リスク(最低3つ)
- 追加で読むべき資料(5つ)
- 最後に「次のアクション案(3つ)」を提案
トーン:ビジネス向け、断定しすぎず根拠ベース
膨大なリソースを調査する際は
人間の限界があります。
調査などに適したモデルもあるので、
最大限に活用できます。
最後に:注意点
生成AIは完璧ではありません。
出力結果は100%信じないように
これはハルシネーションと言われます
ハルシネーションとは、人工知能(AI)が事実に基づかない情報を生成する現象のことです。まるでAIが幻覚(=ハルシネーション)を見ているかのように、もっともらしい嘘(事実とは異なる内容)を出力するため、このように呼ばれています。
OpenAIのChatGPTやGoogle Bardのような会話型AIサービスでは、ユーザーの質問に対してAIが回答しますが、どのようなデータに基づき回答されたのかが分からない場合、それが真実なのか嘘なのか、ユーザーが判断することは困難です。ハルシネーションは、会話型AIサービスの信頼性に関わる問題であり、この問題を解消するために様々な研究が進められています。野村総合研究所より
人間のチェックが必要かつ
成果物を何でもそのまま使うのは危険。
ネットから集める性質上、
嘘が多いのも事実です。
○○を調べてください
公式サイトのみを参照
or
https://*******のみを参照など会話の時に
出典を工夫するのも手です。
まとめ
ChatGPTは
単に“賢いチャット”ではなく、
業務や生活の成果物を作る装置として
使うと強いです。
モデルは“性能比較”よりも、
速さ(Instant)
深さ(Thinking)
調査品質(Pro)
の用途に合わせて切り替えるのがコツ。
使い方次第やプロンプト次第で、
有効な結果が素早く得られるツールです。
無料でも使えますので、
まずは無料枠で有効な使い方を見つけて、
足りない~
となれば
有料に移行できればいいと思います。
次回はGoogle AI Proを契約したので、
Geminiの実力を
ChatGPTと比較して紹介します。
