
こんにちは。tkgです。
前回はpythonを使って、
ExcelデータをGoogleカレンダーへ取り込める設定をメインに紹介させていただきました。

今回は、
実際に取込みに使った簡単なスクリプトやモジュールを紹介していきます。
詳しくないので、基本的に効率的な方法やClass等は使用してません。
フォルダー構成も特に意識していないものです。
 |
 |
ちなみに私はpyqというサービスでpython学びはじめました(継続中)
この辺りは、独学で始めるなら、かなりおすすめなので、
機会があればまた紹介させていただきます。
フォルダー構成
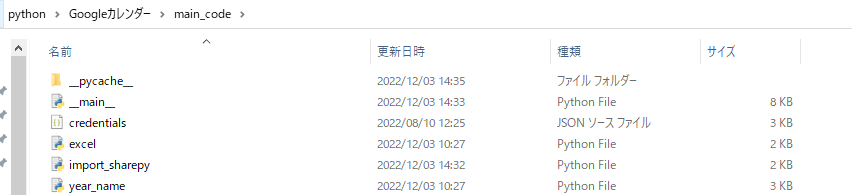
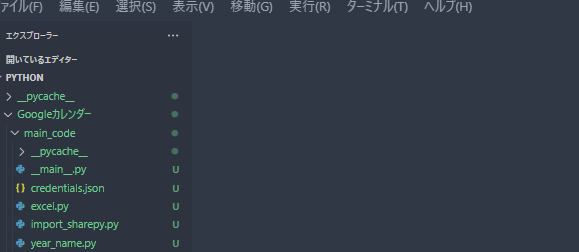
VSコードとWindowsのフォルダー構成は上記みたいに適当に作成してます。
VSコードで「カレンダー」フォルダーと「main_code」フォルダー作成後、
配下に認証キーであるjsonファイル+pythonファイルを4ファイル作成
__main__=実際使用するメインファイル
excel = Excelファイルをデータフレームで整形ファイル
import_sharepy = sharepointにアクセスファイル
year_name = 日付けの整形ファイル
名づけも適当ですけど、とりあえず4ファイルにて動かしてる形です。
各ファイルでの処理内容
sharepointへのアクセス
今回使用したのは、sharepyというライブラリを使って接続してます。
インストール
pip install sharepyVisual Studio Codeでpipを使用できるので、
コマンドラインにて上記でインストールできます。
ライブラリのインポート
import sharepyで使用可能です。
サンプルコード例
import sharepy
from pathlib import Path
import datetime
from pytz import timezone
from dateutil.parser import parse
p = Path(r"ローカルにダウンロードするExcelファイルのパス")
#ダウンロードしているExcelファイルの更新日時の取得
def utc_to_jst(timestamp_utc):
datetime_jst = timestamp_utc.astimezone(datetime.timezone(datetime.timedelta(hours=+9)))
return datetime_jst
update_time = datetime.datetime.fromtimestamp(p.stat().st_mtime)
rocal_excel_time = utc_to_jst(update_time)
#認証
s = sharepy.connect("〇〇※ここは使用する組織で変わる.sharepoint.com",\
username="アクセスネーム", password="アクセスPass")
#Excel情報の取得
i = s.get("https://〇〇.sharepoint.com/_api/web\
/GetFolderByServerRelativeUrl('参照するsharepointフォルダーパス')/Files")
#sharepoint上のExcelファイル更新日時の取得
items = i.json()["d"]["results"]
for row in items:
excel_time = utc_to_jst(parse(row["TimeLastModified"]))
if rocal_excel_time > excel_time:
print("break")
else:
#Download file
r = s.getfile("https://〇〇.sharepoint.com/_api/web\/GetFileByServerRelativeUrl('ダウンロードするsharepointファイルパス')/$value"\
, filename = p)
print(r)
print("Downloaded")ここでは主にsharepointのファイルにアクセス(18~19行目)して、
ローカルにファイルをダウンロードする(33~34行目)スクリプトです。
10~15行・22行目以降:
ここは毎回スクリプト実行都度ダウンロード作業させないように、
sharepoint上のExcelファイルの更新日時に変化ないなら、
ダウンロードしないような条件文記載
※なくても良いし、もっと良いやり方あるかと。
各行説明
def utc_to_jst(timestamp_utc):
datetime_jst = timestamp_utc.astimezone(datetime.timezone(datetime.timedelta(hours=+9)))
return datetime_jst
update_time = datetime.datetime.fromtimestamp(p.stat().st_mtime)
rocal_excel_time = utc_to_jst(update_time)stat().st_mtime = 最終内容更新日時を取得
print(update_time)
2022-12-07 21:03:46.081515
print(rocal_excel_time)
2022-12-07 21:03:46.081515+09:00def文はタイムスタンプ(+09:00)を付けており、
IF文で比較するためにつけてる形です。
sharepy.connect("〇〇※ここは使用する組織で変わる.sharepoint.com",\
username="アクセスネーム", password="アクセスPass")〇〇の部分は組織によって変わります。connect()で接続可能です。
username・passはJSONファイル等で読み込んでもいいですけど、
とりあえずはベタ打ちでやってます。
i = s.get("https://〇〇.sharepoint.com/_api/web\
/GetFolderByServerRelativeUrl('参照するsharepointフォルダーパス')/Files")
#sharepoint上のExcelファイル更新日時の取得
items = i.json()["d"]["results"]GetFolderByServerRelativeUrlでフォルダーパス内の情報取得できます。
i.json()[“d”][“results”]は
ファイル一覧をjsonから抜き出してます。
print(i.json())
{'d': {'results': [{'__metadata': {'id':~~~~~~~省略~~~~~~~~~~~
'TimeCreated': '2022-12-07T07:09:25Z', 'TimeLastModified': '2022-12-07T12:03:33Z',
'Title': '', 'UIVersion': 1024, 'UIVersionLabel': '2.0',
'UniqueId': '*********'}]}}上記のように「i」中身見てみると、
d→resultsでネスト構造からリストで様々な情報が記載されてます。
対象フォルダーにはシフト表のみ入れているので、
シフト表ファイルの情報が取れます。
なので、[‘d’]の中の[‘results’]を抽出。
for row in items:
excel_time = utc_to_jst(parse(row["TimeLastModified"]))
if rocal_excel_time > excel_time:
print("break")
else:
#Download file
r = s.getfile("https://〇〇.sharepoint.com/_api/web\/GetFileByServerRelativeUrl('ダウンロードするsharepointファイルパス')/$value"\
, filename = p)
print(r)
print("Downloaded")目的はファイルに更新日時(TimeLastModified)取得なので、
リストをfor文で展開⇒row[“TimeLastModified”]で辞書内のキーの値を指定し、対象を取得。
print(row["TimeLastModified"])
2022-12-08T00:06:00Z
print(excel_time)
2022-12-08 09:06:00+09:00文字列なので、時間型に変換+日本時間(JST)のタイムゾーンを表記に。
r = s.getfile("https://〇〇.sharepoint.com/_api/web\/GetFileByServerRelativeUrl('ダウンロードするsharepointファイルパス')/$value"\
, filename = p)connectさせたもの(18行)を
getfile()で対象ファイルパス入力でダウンロードできます。
filename = ダウンロードする際の名前やどこにダウンロードするかのパスを入力。
なくても良いですけど、IF文でシフト表が更新されていなかったら、
ダウンロードしないのを29行目あたりで記載してる感じです。
ここまでで、一先ずsharepointの作業は完了。
Excelファイルの中身例

今回は、
上記のような形でExcel上でシフトがある想定です。
- テーブルになってない
- 空白欄に文字や表が入る場合あり
- 名前行に入る名前はシートごとで固定ではない
- 休や明けの文字はなし
- シートタブはどんどん追加される
- シートタブはY年M月で固定だが、仮等の文字が付く場合あり
日数計算
次のファイルでは月ごとの日数や読み込むシートタブの設定をしていってます。
サンプルコード例
import pandas as pd
from datetime import datetime
from datetime import datetime as dt
from dateutil.relativedelta import relativedelta
import calendar
import re
#年や年月日を定義
dt_now = datetime.today()
this_year = dt_now.year
today_month = dt_now.month
next_year_day = datetime.strftime(dt_now + relativedelta( months = 12 ), "%Y")
this_year_sheetname = str(this_year) + "年"
this_next_sheetname = next_year_day + "年"
this_month_after = 12 - dt_now.month
#実行日からの今年分の月抽出
month_after = [f"{this_year_sheetname}{today_month}"]
if this_month_after != 0:
for i in range(this_month_after):
today_month += 1
month_after.append(f"{this_year_sheetname}{today_month}")
#ローカルにダウンロードしたシフトファイルのタブ情報をリストに読み込み
sheet_name_list = pd.ExcelFile(ローカル保存したファイルパス)
sheet_names = sheet_name_list.sheet_names
#タブのリスト内から今年・来年のシートのみを抽出
def year_value():
sheet_name = []
for value in sheet_names:
for rows in month_after:
if rows in value:
sheet_name.append(value)
if this_next_sheetname in value:
sheet_name.append(value)
return sheet_name
#抽出したシートタブから月日を定義したリスト作成
def day_list():
month = []
#抽出したタブを文字列型に変換後に年と月に分けてる
for target_name in year_value():
if re.search("[\d年\d月$]", target_name):
res = re.sub('月.+',"月",target_name)
row = dt.strptime(res, "%Y年%m月")
target_year = row.year
target_month = row.month
#抽出タブ年月の日情報を抽出し、年月を結合しtxtに反映させる形式に変換しリストにいれてる
for i in range(calendar.monthrange(target_year, target_month)[1]):
month_days = f"{str(target_year)}/{str(target_month)}/{str(i + 1)}"
month.append(month_days)
return monthとりあえず適当ではありますが、上記のように作成。
dt_now = datetime.today()
this_year = dt_now.year
today_month = dt_now.month
next_year_day = datetime.strftime(dt_now + relativedelta( months = 12 ), "%Y")
this_year_sheetname = str(this_year) + "年"
this_next_sheetname = next_year_day + "年"この辺りは、今日の日付から(9行目)年月日を抽出してます。
relativedelta()は年月日の計算ができるので、
来年の年のみを抽出するために12カ月足してる形です。
this_month_after = 12 - dt_now.month15行目は過去のシートタブを参照しないように、
現在月から先のシートを抽出するように意図的に残り月数を計算してます。
month_after = [f"{this_year_sheetname}{today_month}"]
if this_month_after != 0:
for i in range(this_month_after):
today_month += 1
month_after.append(f"{this_year_sheetname}{today_month}")
#今が10月の場合
print(month_after)
['2022年10','2022年11','2022年12']この辺りはスマートではないですけど、
今月分のシートをリストに入れといて、
残り月数分をmonthに1足してリストに入れていってる形です。
sheet_name_list = pd.ExcelFile(ローカル保存したファイルパス)
sheet_names = sheet_name_list.sheet_names
print(sheet_names)
['2021年3月', '2021年4月', '2021年5月', '2021年6月', '2021年7月',
'2021年8月', '2021年9月', '2021年10月', '2021年11月', '2021年12月',
'2022年1月', '2022年2月', '2022年3月', '2022年4月', '2022年5月',
'2022年6月', '2022年7月', '2022年8月', '2022年9月', '2022年10月',
'2022年11月', '2022年12月', '2023年1月仮', 'フォーマット', '祝日']pdがExcelファイルを操作するPandasと呼ばれるライブラリで、
Excel操作するのに便利なものです。

.sheet_namesでExcelのすべてのシートタブ抽出できますね。
def year_value():
sheet_name = []
for value in sheet_names:
for rows in month_after:
if rows in value:
sheet_name.append(value)
if this_next_sheetname in value:
sheet_name.append(value)
return sheet_name
print(year_value())
['2022年12月', '2023年1月仮']この辺りは、入れ子になってしまいましたが、
Excelの抽出タブ内に、先ほどの18行目の文字列があれば、
sheet_nameに入れていって、来年のシートがあればそれも追加という感じで、
これで、すべてのシートを参照せずに、
開いた月から最新の月までのシートタブの抽出ができました。
def day_list():
month = []
#抽出したタブを文字列型に変換後に年と月に分けてる
for target_name in year_value():
if re.search("[\d年\d月$]", target_name):
res = re.sub('月.+',"月",target_name)
row = dt.strptime(res, "%Y年%m月")
target_year = row.year
target_month = row.monthこの辺りは、対象月の日付を抽出するために年月を抽出。
シートタブ名が年月日後は変わる場合あり他のシート名を追加される可能性あるので、
re.searchで○○年○○月に絞り
re.subで「仮」とかの文字をとりあえず消してます。
その後、また抽出したシート名を年月に分けた、datatime型に変換してます。
for i in range(calendar.monthrange(target_year, target_month)[1]):
month_days = f"{str(target_year)}/{str(target_month)}/{str(i + 1)}"
month.append(month_days)
return monthここは対象シート名の年と月をすべてリストに入れる作業をしてます。
calendar.monthrange(年,月)[1]で日数取得できます。
これをrange分回して、文字列で足すような作業((i + 1))でとりあえず実装。
print(day_list())
['2022/12/1', '2022/12/2', '2022/12/3', '2022/12/4', '2022/12/5', '2022/12/6',
'2022/12/7', '2022/12/8', '2022/12/9', '2022/12/10', '2022/12/11', '2022/12/12',
'2022/12/13', '2022/12/14', '2022/12/15', '2022/12/16', '2022/12/17', '2022/12/18',
'2022/12/19', '2022/12/20', '2022/12/21', '2022/12/22', '2022/12/23', '2022/12/24',
'2022/12/25', '2022/12/26', '2022/12/27', '2022/12/28', '2022/12/29', '2022/12/30',
'2022/12/31', '2023/1/1', '2023/1/2', '2023/1/3', '2023/1/4', '2023/1/5', '2023/1/6',
'2023/1/7', '2023/1/8', '2023/1/9', '2023/1/10', '2023/1/11', '2023/1/12', '2023/1/13',
'2023/1/14', '2023/1/15', '2023/1/16', '2023/1/17', '2023/1/18', '2023/1/19', '2023/1/20',
'2023/1/21', '2023/1/22', '2023/1/23', '2023/1/24', '2023/1/25', '2023/1/26', '2023/1/27',
'2023/1/28', '2023/1/29', '2023/1/30', '2023/1/31']これで、今月~最新のシートまでの日数情報をリストに入れ込むことに成功。
効率とか難しいことはできないので、まぁとりあえず抽出できてるから
良しとしような感じです。
Excelファイル操作
pandasを使用して対象の行情報の取得しています。
サンプルコード
import import_sharepy
import year_name
import pandas as pd
import re
path = ローカル保存したエクセルのパス
#自分の情報列だけ抽出
def excel_value():
excel_list = []
#抽出したタブ情報をデータフレームに
for sheet in year_name.year_value():
df = pd.read_excel(path, sheet_name=sheet, header = 1, index_col=1, skiprows=1, skipfooter=5,)
#不要列の削除
for col in df.columns:
if re.search('[^\d]+', str(col)):
del df[col]
#ヘッダー抜きの列情報だけ抽出・整形しリストにいれる
for d,x in df.iteritems():
row = str(x.loc["対象の名前"])
#データの名称を変更
row = row.replace("nan","休")
row = row.replace("有","有給")
row = row.replace("朝", "朝勤")
row = row.replace("夜", "夜勤")
row = row.replace("後", "午後休")
row = row.replace("前", "午前休")
excel_list.append(row)
return excel_list
#明けを明記するため、文字列に変換語に正規表現にて変換
def shift_pattern():
res_str = " ".join(excel_value())
res = re.sub("夜勤\s+(休|有給)", "夜勤 明け", res_str)
shift_list = res.split()
return shift_list
#抽出した年月日のリストとタブ抽出し整形したリストを対応する辞書に変換
def dict_values():
dict_data = dict(zip(year_name.day_list(), shift_pattern()))
return dict_dataここでは最終的に、
「日付:勤務帯」を辞書形式で抽出するようにしています。
for sheet in year_name.year_value():
df = pd.read_excel(path, sheet_name=sheet, header = 1, index_col=1, skiprows=1, skipfooter=5,)12~13行目:
前回のシートタブ情報をまずは展開。
pd.read_excel(ファイルパス, シートタブ名称)でデータフレームというデータ構造にして、
データ分析をしやすくしています。
sheet_name=sheet で対象月のみ読み込み
header=はどの行をcolumnsにするか設定
index_col=はその列をindexにするか設定
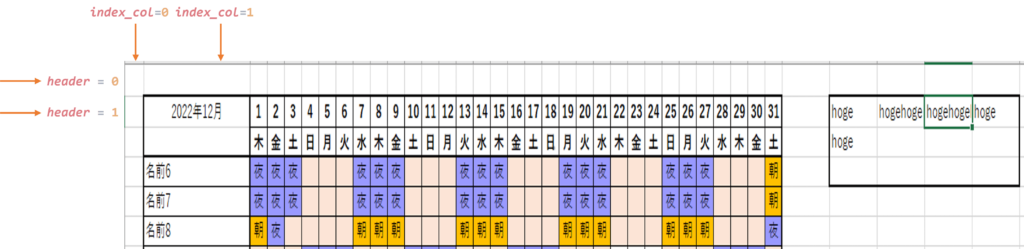
先頭行や先頭列を指定しておくと、対象のセルを抽出するのに便利です。
skiprows=〇は読み込まない先頭行指定
skipfooter=〇は読み込まない下部行指定

一行目いらないとか下のデータいらないみたいなのを、
先に指定しておけます。
結果、日付部分(Excel3行目)をcolumns
B列の名前部分をindexとして定義。
print(df.columns)
Index([ 'Unnamed: 0', 44927, 44928, 44929,
44930, 44931, 44932, 44933,
44934, 44935, 44936, 44937,
44938, 44939, 44940, 44941,
44942, 44943, 44944, 44945,
44946, 44947, 44948, 44949,
44950, 44951, 44952, 44953,
44954, 44955, 44956, 44957,
'Unnamed: 33', 'Unnamed: 34', 'Unnamed: 35', 'Unnamed: 36',
'Unnamed: 37', 'Unnamed: 38']
#日付は関数あるので、数値になっている。
#列に記載あるけど、空白になってるところはUnnamedで抽出
print(df.index)
Index(['名前6', '名前7', '名前8',
'名前9', '名前10', '名前11', '名前13', '名前14', '名前15'], dtype='object')
#名前の行がindexとして抽出されます。これを組み合わせて、名前1,indexの名称を指定すれば、
該当のセルの値も取得できます。
for col in df.columns:
if re.search('[^\d]+', str(col)):
del df[col]15行目あたりは、先ほど抽出したcolumns(列)から
不要な列を正規表現で削除してます。
for d,x in df.iteritems():
row = str(x.loc["対象の名前"])
#データの名称を変更
row = row.replace("nan","休")
row = row.replace("有","有給")
row = row.replace("朝", "朝勤")
row = row.replace("夜", "夜勤")
row = row.replace("後", "午後休")
row = row.replace("前", "午前休")
excel_list.append(row)完成したデータフレームから実際の列情報を抜き出すのが
19行目以降です。
左のカラムから順にループ(iteritems())させ、
loc[“対象の名前”]で対象のindexの名前の列を抽出。
for d,x in df.iteritems():
row = str(x.loc["名前11"])
print(row)
朝
朝
朝
nan
nan
nan
朝
朝
有
etc上記の場合は、このように対象行が取得できました。
22行目以降は自身の形態に合わせて好きなように変更しているだけです。
データ空白行は”nan”として出力されるので、
休とかで整形してます。
print(excel_list())
['朝勤', '朝勤', '朝勤', '休', '休', '休', '朝勤', '朝勤', '有給', '休', '休', '休', '朝勤', '朝勤', '朝勤', '休', '休', '休', '朝勤', '朝勤', '朝勤', '休', '休', '休',
'朝勤', '午後休', '朝勤', '休', '休', '休', '有給']例えば、「名前11]行なら上記のように整形された形でリスト形式に。
33~37行目は夜勤の「明け」を明記するために、
勤務のリストを文字列にした上で、re.subで変換後に
再度リストに加える処理を実施。
print(shift_pattern())
[~~, '夜勤', '夜勤', '明け', '休', '休', '夜勤', '夜勤', '夜勤', '明け', '休', '休',
'夜勤', '夜勤', '夜勤', '明け', '休', '休', '夜勤', '夜勤',
'夜勤', '明け', '休', '休', '朝勤', '朝勤']これで、夜勤の後の休みを明けに変換できました。
def dict_values():
dict_data = dict(zip(year_name.day_list(), shift_pattern()))
return dict_data
print(dict_values())
{'2022/12/1': '朝勤', '2022/12/2': '朝勤', '2022/12/3': '朝勤', '2022/12/4': '休',
'2022/12/5': '休', '2022/12/6': '休', '2022/12/7': '朝勤', '2022/12/8': '朝勤',
'2022/12/9': '朝勤', '2022/12/10': '休', '2022/12/11': '休', '2022/12/12': '休',
'2022/12/13': '有給', '2022/12/14': '朝勤', '2022/12/15': '朝勤', '2022/12/16': '休',
'2022/12/17': '休', '2022/12/18': '休', '2022/12/19': '朝勤', '2022/12/20': '朝勤',
'2022/12/21': '朝勤', '2022/12/22': '休', '2022/12/23': '休', '2022/12/24': '休',
'2022/12/25': '朝勤', '2022/12/26': ' 午後休', '2022/12/27': '朝勤', '2022/12/28': '休',
'2022/12/29': '休', '2022/12/30': '休', '2022/12/31': '有給',~~~}上記は、日数計算のday_list()とshift_pattern()を連結させて、
辞書のkeyとvalueにしてます。
ここでExcelファイルから取り出した勤務形態のデータ整形終わりです。
もっといいやり方、無駄処理は多いですが、初心者なので悪しからず。
|
|
Googleカレンダーへの取り込み
前回の取り込み設定をカスタマイズしてExcelから抽出したデータを
Googleカレンダーへ取り込んでいきます。
サンプルコード
import re
import google.auth
import googleapiclient.discovery
import datetime
import year_name
import excel
import itertools
import sys
import json
import os
# 編集スコープの設定(今回は読み書き両方OKの設定)
SCOPES = ['https://www.googleapis.com/auth/calendar']
# カレンダーIDの設定(基本的には自身のgmailのアドレス)
calendar_id = '****************'
# 認証ファイルを使用して認証用オブジェクトを作成
gapi_creds = google.auth.load_credentials_from_file("jsonファイルのパス", SCOPES)[0]
# 認証用オブジェクトを使用してAPIを呼び出すためのオブジェクト作成
service = googleapiclient.discovery.build('calendar', 'v3', credentials=gapi_creds)
#カレンダに登録されてる予定の取得(取得したエクセルの日数を抽出)
#this_min = datetime.datetime.strptime(year_name.day_list()[0], '%Y/%m/%d').isoformat()+'Z'
#⇒上記も前日に設定しておかないと、月初めが終日予定の場合検出されないので修正。
#EXCELデータ上の当月の月初めとシートタブ月最後の日を抽出
list_min = datetime.datetime.strptime(year_name.day_list()[0], '%Y/%m/%d')
list_max = datetime.datetime.strptime(year_name.day_list()[-1], '%Y/%m/%d')
#当月の月初め一日前とシートタブ月最後の日の一日後を設定
row_min = list_min - datetime.timedelta(days=1)
row_max = list_max + datetime.timedelta(days=1)
#カレンダー形式に変換
this_min = row_min.isoformat()+'Z'
this_max = row_max.isoformat()+'Z'
#Googleカレンダー上の予定を抽出
events_list = service.events().list(
calendarId=calendar_id,
timeMin=this_min,
timeMax=this_max,
singleEvents=True,
orderBy="startTime"
).execute()
events = events_list.get('items', [])
#追加するスケジュールの情報を設定
#エクセルの情報を辞書変換したものをgooleのフォマートに整形
#時間は形態毎+勤務形態は取得したエクセルタイトルに準拠
def google_format():
body_res = []
for key, values in excel.dict_values().items():
body = {
#予定のタイトル
'summary': '',
#予定の色
"colorId": '',
# 予定の開始時刻
'start': {
'dateTime': "",
'timeZone': 'Japan'
},
#予定の終了時刻
'end': {
'dateTime': "",
'timeZone': 'Japan'
},
}
body["summary"] = values
shift_date = datetime.datetime.strptime(key, '%Y/%m/%d')
if values == "朝勤":
morning_start = shift_date.replace(hour=〇)
morning_end = shift_date.replace(hour=〇, minute=〇)
body["start"]["dateTime"] = morning_start.isoformat()
body["end"]["dateTime"] = morning_end.isoformat()
body["colorId"] = "6"
elif values == "夜勤":
#うるう年とそうでないのを見分けるため
calendar_days = shift_date + datetime.timedelta(days=1)
body["summary"] = values
evening_start = shift_date.replace(hour=〇)
evening_end = shift_date.replace(year=calendar_days.year, month=calendar_days.month, day=calendar_days.day, hour=〇, minute=〇)
body["start"]["dateTime"] = evening_start.isoformat()
body["end"]["dateTime"] = evening_end.isoformat()
body["colorId"] = "3"
elif values == "明け":
evening_rest_start = shift_date.replace(hour=〇, minute=〇)
evening_rest_end = shift_date.replace(hour=〇, minute=〇)
body["start"]["dateTime"] = evening_rest_start.isoformat()
body["end"]["dateTime"] = evening_rest_end.isoformat()
body["colorId"] = "2"
elif values == "午後休":
afterhalf_start = shift_date.replace(hour=〇)
afterhalf_end = shift_date.replace(hour=〇)
body["start"]["dateTime"] = afterhalf_start.isoformat()
body["end"]["dateTime"] = afterhalf_end.isoformat()
body["colorId"] = "9"
elif values == "午前休":
beforehalf_start = shift_date.replace(hour=〇, minute=〇)
beforehalf_end = shift_date.replace(hour=〇, minute=〇)
body["start"]["dateTime"] = beforehalf_start.isoformat()
body["end"]["dateTime"] = beforehalf_end.isoformat()
body["colorId"] = "5"
elif values == "休" or values == "有給":
body["start"]["dateTime"] = shift_date.date().isoformat()
body["end"]["dateTime"] = shift_date.date().isoformat()
body["colorId"] = "11"
else:
body["start"]["dateTime"] = shift_date.date().isoformat()
body["end"]["dateTime"] = shift_date.date().isoformat()
body["colorId"] = "1"
body_res.append(body)
return body_res
# 終日設定
def end_day():
body_list = []
for body_row in google_format():
if not (body_row["summary"] == "朝勤" or body_row["summary"] == "夜勤"
or body_row["summary"] == "明け" or body_row["summary"] == "午後休"
or body_row["summary"] == "午前休"):
body_row["start"]["date"] = body_row["start"]["dateTime"]
body_row["end"]["date"] = body_row["end"]["dateTime"]
del body_row["start"]["dateTime"]
del body_row["end"]["dateTime"]
body_list.append(body_row)
return body_list
#エクセルの日付+予定データに変換
def excel_data_list():
excel_list = []
for i in end_day():
excel_start = i['start'].get('dateTime', i["start"].get("date"))
res_start = re.sub(r"T\S+$", "", excel_start)
res_str_start = res_start + i["summary"]
excel_list.append(res_str_start)
return excel_list
#カレンダーの日付+予定データに変換
def calender_data_list():
calendar_list = set([])
for x in events:
event_start = x['start'].get('dateTime', x["start"].get("date"))
re_start = re.sub(r"T\S+$", "", event_start)
re_str_start = re_start + x["summary"]
calendar_list.add(re_str_start)
return calendar_list
#エクセル・カレンダーの差分の日付+予定を抽出
calendar_diff = set(excel_data_list()) ^ calender_data_list()
#登録されてるイベントとシフトデータを比較し重複予定の洗い出し
#リストにシフトの差分のみのデータ取得
def change_data_list():
new_list = []
change_shift = []
for new in calendar_diff:
if re.match(r".*[夜勤|朝勤|明け|休|午後休|午前休|有給]", new):
new_date = re.sub(r"\D{1,5}$", "", new)
new_list.append(new_date)
for v, x in itertools.product(end_day(), new_list):
new_start = v['start'].get('dateTime', v["start"].get("date"))
if x in new_start and re.match(r"[夜勤|朝勤|明け|休|午後休|午前休|有給]", v["summary"]):
change_shift.append(v)
unique_list = list(map(json.loads, set(map(json.dumps, change_shift))))
return unique_list
#差分の予定分をカレンダーから削除
def calendar_duplication():
dup_list = []
dup_shift = []
for new in calendar_diff:
if re.match(r".*[夜勤|朝勤|明け|休|午後休|午前休|有給]", new):
new_date = re.sub(r"\D{1,5}$", "", new)
dup_list.append(new_date)
for v, x in itertools.product(events, dup_list):
new_start = v['start'].get('dateTime', v["start"].get("date"))
if x in new_start and re.match(r"[夜勤|朝勤|明け|休|午後休|午前休|有給]", v["summary"]):
dup_shift.append(v)
unique_list = list(map(json.loads, set(map(json.dumps, dup_shift))))
return unique_list
def main():
#リスト内に予定があるかどうかで分岐させている
def main_dup():
if calendar_duplication():
for dup_row in calendar_duplication():
events = service.events().delete(calendarId=calendar_id, eventId=dup_row["id"]).execute()
print(events)
def main_add():
if change_data_list():
for add_row in change_data_list():
events = service.events().insert(calendarId=calendar_id, body=add_row).execute()
print(events)
return main_dup(), main_add()
if __name__ == "__main__":
main() 主にGoogleフォーマットに整形するコードと、重複予定を登録しないようなコードを記載しました。
14行目~22行目は前回のAPI時に記載した、
認証コードとなります。
list_min = datetime.datetime.strptime(year_name.day_list()[0], '%Y/%m/%d')
list_max = datetime.datetime.strptime(year_name.day_list()[-1], '%Y/%m/%d')
row_min = list_min - datetime.timedelta(days=1)
row_max = list_max + datetime.timedelta(days=1)
this_min = row_min.isoformat()+'Z'
this_max = row_max.isoformat()+'Z'
events_list = service.events().list(
calendarId=calendar_id,
timeMin=this_min,
timeMax=this_max,
singleEvents=True,
orderBy="startTime"
).execute()
events = events_list.get('items', [])ここはカレンダーイベントを取得するスクリプトです。
service.events().list()で取得可能。

timeMin=とtimeMax=で取得する期間を設定するため、
年月日計算のday_listから最初の日付と最後の日付を抽出。
0:00で抽出されるので、日にちを一日足した形にしています。
timeMinも同様にしないといけない。
list_min = datetime.datetime.strptime(year_name.day_list()[0], '%Y/%m/%d') + .isoformat()+'Z'
print(list_min)
2023-01-01T00:00:00Zになるが、そうすると、1日が終日予定の場合、
31日0時~1日0時までの分は抽出されない=2日から抽出される。
逆に一日引いた形で「2022-12-31T00:00:00Z」から抽出してあげればOKです。
isoformat()+’Z’は日時はiso規格じゃないとダメそうなので、
変換しています。
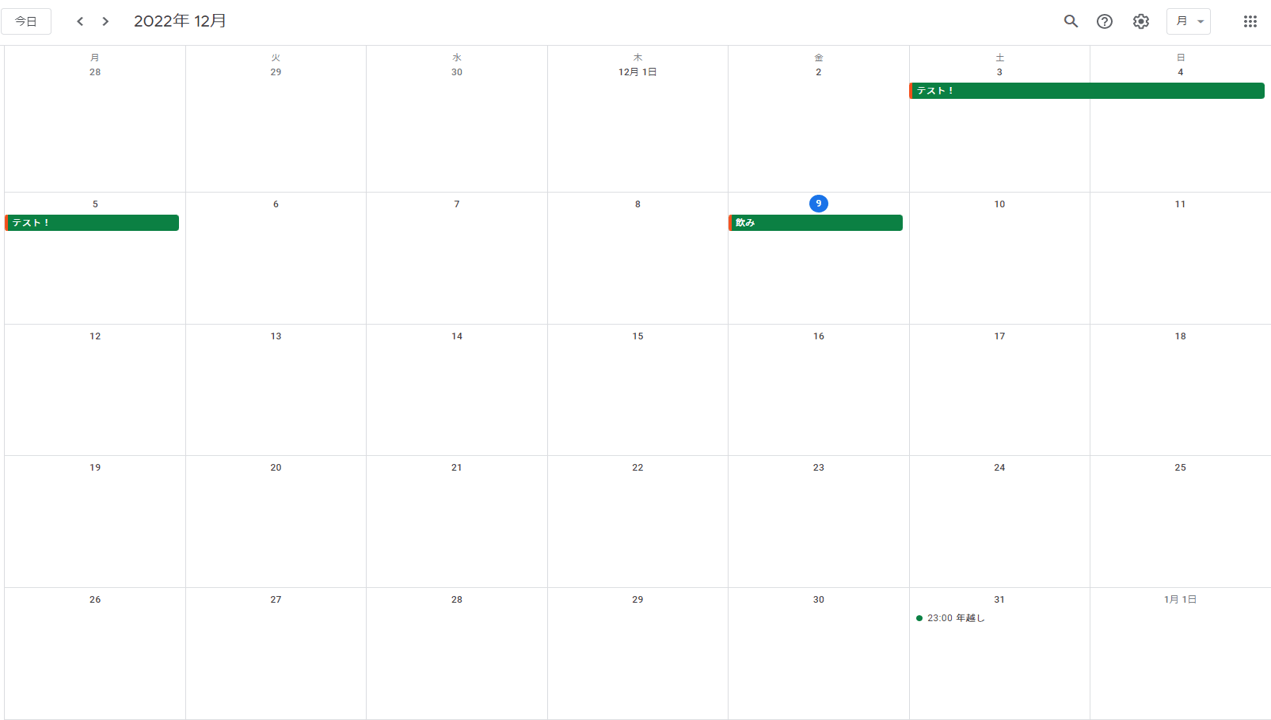
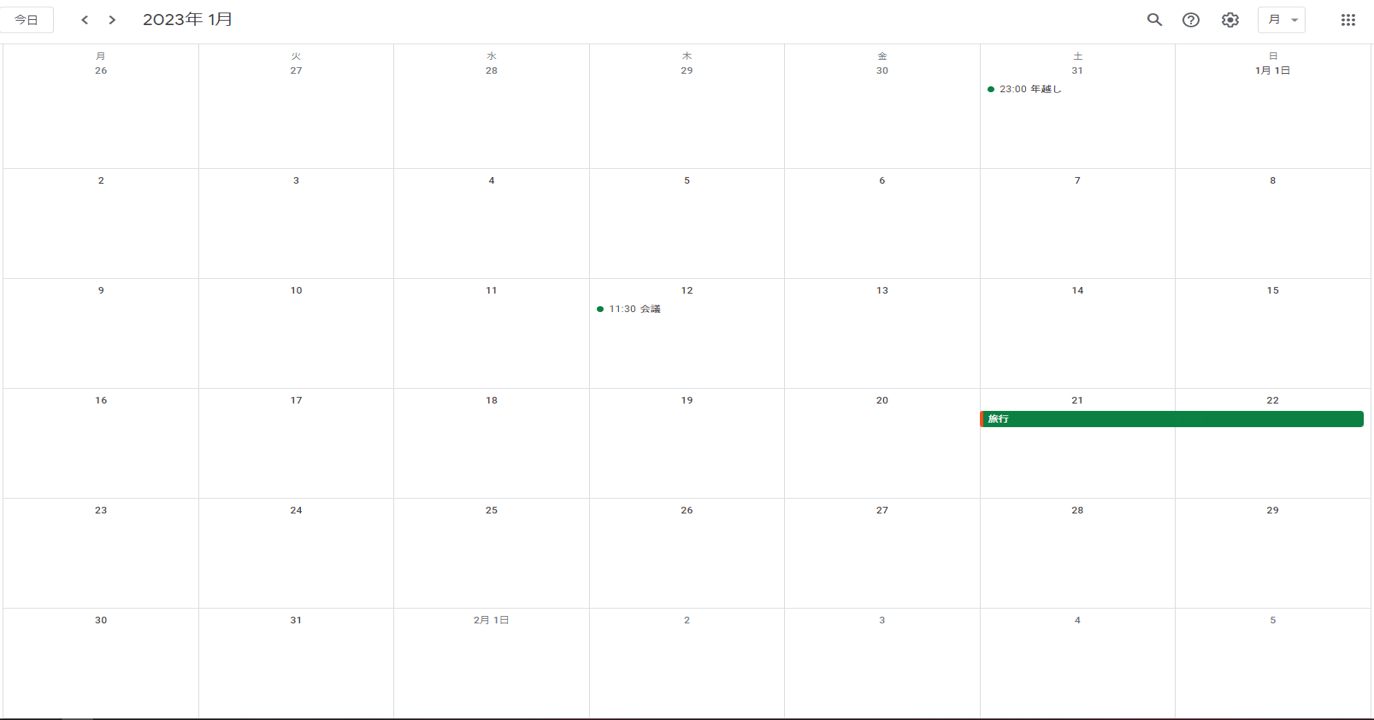
#Excelの読み込むシートタブから
#最初の日付と最後に日付取得
print(this_min)
2022-12-01T00:00:00Z
print(this_max)
2023-02-01T00:00:00Z
#いろんな情報が辞書で取得可能
print(events)
'items': [{'kind': 'calendar#event', 'etag': '"3340121687092000"',
'id': '6t5cl4v78konf6doqssj0uho7s', 'status': 'confirmed',
'htmlLink': 'https://www.google.com/******', 'created': '2022-12-03T09:01:12.000Z',
'updated': '2022-12-03T09:47:23.546Z', 'summary': 'テスト!', 'colorId': '10',
'creator': {'email': '*********'}, 'organizer': {'email': '****@gmail.com', 'self': True},
'start': {'dateTime': '2022-12-03T00:00:00+09:00', 'timeZone': 'Asia/Tokyo'},
'end': {'dateTime': '2022-12-05T17:59:00+09:00', 'timeZone': 'Asia/Tokyo'},~~~
#整形すると
format_events = [(event['start'].get('dateTime', event['start'].get('date')),
event['end'].get('dateTime', event['end'].get('date')),
event['summary']) for event in events]
print(format_events)
[('2022-12-03T00:00:00+09:00', '2022-12-05T17:59:00+09:00', 'テスト!'),
('2022-12-09', '2022-12-10', '飲み'),
('2022-12-31T23:00:00+09:00', '2023-01-01T02:00:00+09:00', '年越し'),
('2023-01-12T11:30:00+09:00', '2023-01-12T12:30:00+09:00', '会議'),
('2023-01-21', '2023-01-23', '旅行')]このようにカレンダーイベントを取得できました。
def google_format():
body_res = []
for key, values in excel.dict_values().items():
body = {
#予定のタイトル
'summary': '',
#予定の色
"colorId": '',
# 予定の開始時刻
'start': {
'dateTime': "",
'timeZone': 'Japan'
},
#予定の終了時刻
'end': {
'dateTime': "",
'timeZone': 'Japan'
},
}
body["summary"] = values
shift_date = datetime.datetime.strptime(key, '%Y/%m/%d')ここは予定追加フォーマットにエクセルで取得したものを
入れた上で、リストに格納する処理です。
colorも設定できるので、フォーマットに入れてます。
excel.dict_values().items()でEXCELデータの辞書をそれぞれ分けてます。
body[“summary”] = valuesで
Excelの予定部分をタイトルである”summary”に
挿入してる形です。
shift_dateは日付けを扱いやすいようにdatetime形式にしてます。
if values == "朝勤":
morning_start = shift_date.replace(hour=〇)
morning_end = shift_date.replace(hour=〇, minute=〇)
body["start"]["dateTime"] = morning_start.isoformat()
body["end"]["dateTime"] = morning_end.isoformat()
body["colorId"] = "6"
if ~~~62行目以降はタイトル毎に時間や色を設定し、
フォーマットに入れていってます。
タイトル=valuesが〇〇なら
開始時間は〇〇~終了時間は○○で色はこの色みたいな形です。
また翌日まで続く場合は
calendar_days = shift_date + datetime.timedelta(days=1)のように日付を一日足した状態の変数を指定した上で、
dayを定義しています。
こうすることで、うるう年にも対応できます。
日を+1するだけだと、年を指定してなければ、2月は29日も出現してしまい、
28日の場合はそんな日付ないよ!ってなります。
色コード番号は以下参照。

else:部分は、
その他のタイトルなら終日予定で色も統一するようなコードです。
def end_day():
body_list = []
for body_row in google_format():
if not (body_row["summary"] == "朝勤" or body_row["summary"] == "夜勤"
or body_row["summary"] == "明け" or body_row["summary"] == "午後休"
or body_row["summary"] == "午前休"):
body_row["start"]["date"] = body_row["start"]["dateTime"]
body_row["end"]["date"] = body_row["end"]["dateTime"]
del body_row["start"]["dateTime"]
del body_row["end"]["dateTime"]
body_list.append(body_row)
return body_listここでは終日予定の設定をどうにかして実施してます。
Googleの終日予定と期間予定とではプロパティが少し違います。
#終日予定
'start': {'date': '2023-01-21'}, 'end': {'date': '2023-01-23'}
#期間予定
'start': {'dateTime': '2023-01-12T11:30:00+09:00', 'timeZone': 'Asia/Tokyo'},
'end': {'dateTime': '2023-01-12T12:30:00+09:00', 'timeZone': 'Asia/Tokyo'}dateTimeのキーだったのが、終日予定では
dateキーで変更しなければなりません。
シフトでも「休み」「有給」を終日予定にしたかったので、
google_format()で作成したものから、タイトルを拾って、
108行目以降のif not 分で抽出してます。
111~114行目は無理やりですが、Hitするものは
dateTimeのキーをdateキー変更した上で、
delで元のdateTimeのキーを消してる感じです。
print(end_day())
[{'summary': '朝勤', 'colorId': '6', 'start': {'dateTime': '2022-12-01T10:00:00', 'timeZone': 'Japan'},
'end': {'dateTime': '2022-12-01T22:30:00', 'timeZone': 'Japan'}},
{'summary': '朝勤', 'colorId': '6', 'start': {'dateTime': '2022-12-02T10:00:00', 'timeZone': 'Japan'},
'end': {'dateTime': '2022-12-02T22:30:00', 'timeZone': 'Japan'}},
{'summary': '朝勤', 'colorId': '6', 'start': {'dateTime': '2022-12-03T10:00:00', 'timeZone': 'Japan'},
'end': {'dateTime': '2022-12-03T22:30:00', 'timeZone': 'Japan'}},
{'summary': '休', 'colorId': '11', 'start': {'timeZone': 'Japan', 'date': '2022-12-04'},
'end': {'timeZone': 'Japan', 'date': '2022-12-04'}},
{'summary': '休', 'colorId': '11', 'start': {'timeZone': 'Japan', 'date': '2022-12-05'},
'end': {'timeZone': 'Japan', 'date': '2022-12-05'}},
{'summary': '休', 'colorId': '11', 'start': {'timeZone': 'Japan', 'date': '2022-12-06'},
'end': {'timeZone': 'Japan', 'date': '2022-12-06'}}, ~~~~}]これでなんとか休みをdateに変換でGoogleフォーマットに入れる準備はできました。
119行目からはスクリプト走らせると、
同じ予定がどんどん追加されるのをなんとかしようというブロックです。
まずは、Excel予定とカレンダ予定の差分を見て、
差分がある予定だけ抽出。
その日のシフトに関する予定を削除した上で追加するという方法でなんとか実現してます。
def excel_data_list():
excel_list = []
for i in end_day():
excel_start = i['start'].get('dateTime', i["start"].get("date"))
res_start = re.sub(r"T\S+$", "", excel_start)
res_str_start = res_start + i["summary"]
excel_list.append(res_str_start)
return excel_listExcelの予定リストを日付+予定のリストに変換。
print(excel_data_list())
['2022-12-01朝勤', '2022-12-02朝勤', '2022-12-03朝勤', '2022-12-04休',
'2022-12-05休', '2022-12-06休', '2022-12-07朝勤', '2022-12-08朝勤',
'2022-12-09朝勤', '2022-12-10休', '2022-12-11休', '2022-12-12休',~~]同様にカレンダーイベントも日付+予定のリストに変換。
def calender_data_list():
calendar_list = set([])
for x in events:
event_start = x['start'].get('dateTime', x["start"].get("date"))
re_start = re.sub(r"T\S+$", "", event_start)
re_str_start = re_start + x["summary"]
calendar_list.add(re_str_start)
return calendar_listprint(calender_data_list())
{'2023-01-12会議', '2022-12-03テスト!', '2023-01-21旅行', '2022-12-09飲み', '2022-12-31年越し'}上記二つのリストをsetの集合型で差分取得。
#対称差集合(どちらか一方にだけ含まれる要素の集合)^
calendar_diff = set(excel_data_list()) ^ calender_data_list()
print(calendar_diff)
{'2022-12-01朝勤', '2023-01-01有給',
'2022-12-03朝勤', '2022-12-12休', '2023-01-25夜勤', '2023-01-19夜勤', ~~}これで追加が必要なものだけを取得できました。
なので、Excelのシフト表で自身の欄を「朝勤」→「休」に変更すれば、
Excelリストの日付+休が表示されます。
def change_data_list():
new_list = []
change_shift = []
for new in calendar_diff:
if re.match(r".*[夜勤|朝勤|明け|休|午後休|午前休|有給]", new):
new_date = re.sub(r"\D{1,5}$", "", new)
new_list.append(new_date)
for v, x in itertools.product(end_day(), new_list):
new_start = v['start'].get('dateTime', v["start"].get("date"))
if x in new_start and re.match(r"[夜勤|朝勤|明け|休|午後休|午前休|有給]", v["summary"]):
change_shift.append(v)
unique_list = list(map(json.loads, set(map(json.dumps, change_shift))))
return unique_list差分を取ったものを、143行目以降で、加えるものだけに成形したデータを、
Googleフォーマット形式に変換しています。
146行目ブロックでタイトルの予定があれば、
日付けのみを抽出するようにしてます。
print(new_list)
['2022-12-08', '2022-12-19', '2023-01-10', '2022-12-21', '2023-01-26',~~]150行目のブロックでは、
Excelリスト(end_day())から日付けのみを抽出し、
152行目で差分抽出した日付けのGoogleフォーマットのExcelデータを
リストに加える処理。
これだと、差分した日付けデータ(エクセルデータ)を
辞書に追加してるだけなので、重複してしまいます。
元からあるExcelのデータ+今回で差分日付けのExcelデータが
二重でリストに加えられます。
unique_list = list(map(json.loads, set(map(json.dumps, change_shift))))ここの処理で、重複予定を削除してます。
あくまで、ここはシフト原本が正で、カレンダー上でシフト書き換えても
修正されるようにしていたり、個人予定で差分が抽出されても、
タイトルで制御してるので、個人予定は無視される形です。
Excelの予定変更したら、カレンダーの予定と違うよね!
なので、その予定をExcelの予定で書きだすね!って感じにしてるつもりですけど、
もっとやり方はあるかと。
def calendar_duplication():
dup_list = []
dup_shift = []
for new in calendar_diff:
if re.match(r".*[夜勤|朝勤|明け|休|午後休|午前休|有給]", new):
new_date = re.sub(r"\D{1,5}$", "", new)
dup_list.append(new_date)
for v, x in itertools.product(events, dup_list):
new_start = v['start'].get('dateTime', v["start"].get("date"))
if x in new_start and re.match(r"[夜勤|朝勤|明け|休|午後休|午前休|有給]", v["summary"]):
dup_shift.append(v)
unique_list = list(map(json.loads, set(map(json.dumps, dup_shift))))
return unique_listここは反対に消す予定を取得して、リストにしてます。
change_data_list()同様、差分日付け取得。
165行目はカレンダー予定の中から、日付に対応した予定リストを取得してます。
#13日は朝勤としていたが、夜勤になり
#シフト表を夜勤にした場合
print(calendar_duplication())
'summary': '朝勤', 'colorId': '5', 'creator': {'email': '****@gmail.com', 'self': True},
'organizer': {'email': '****@gmail.com', 'self': True},
'start': {'dateTime': '2023-01-13T10:30:00+09:00', 'timeZone': 'Asia/Tokyo'},
'end': {'dateTime': '2023-01-13T22:30:00+09:00', 'timeZone': 'Asia/Tokyo'}, ここまでで、
change_data_list()でGoogleフォーマット形式で
シフトから抽出した加えるべきものを抽出。
calendar_duplication()でGoogleカレンダーから
削除する予定を抽出できました。
def main():
#リスト内に予定があるかどうかで分岐させている
def main_dup():
if calendar_duplication():
for dup_row in calendar_duplication():
events = service.events().delete(calendarId=calendar_id, eventId=dup_row["id"]).execute()
print(events)
def main_add():
if change_data_list():
for add_row in change_data_list():
events = service.events().insert(calendarId=calendar_id, body=add_row).execute()
print(events)
return main_dup(), main_add()ここで先ほど抽出したものを加えるor削除するスクリプトを記載。
def main_dup():
if calendar_duplication():
for dup_row in calendar_duplication():
events = service.events().delete(calendarId=calendar_id, eventId=dup_row["id"]).execute()イベントを消すものあれば、
events = service.events().deleteでその予定を削除する感じです。
eventId=dup_row[“id”]ですが、
イベント削除するために、イベントIDが必要なので、
なので、calendar_duplication()でリストに書き出して、
当てはめていってます。
def main_add():
if change_data_list():
for add_row in change_data_list():
events = service.events().insert(calendarId=calendar_id, body=add_row).execute()予定削除後に、差分データで追加するものあれば、
service.events().insert()で追加していってる形です。
とまぁ無駄処理も多かったり、スマートな方法ではないですけど、
4つのファイルで
sharepoint上Excel更新で
Googleカレンダー更新という目的が達成できました。

とりあえず今回はGoogleカレンダーへの取り込みをする
スクリプト例を紹介させていただきました。
細かい部分を弄れば、自身にあったシフト・予定取込を行えると思います。
次回は本スクリプトをWindows上で自動化する設定を紹介させていただきます。
コメント